Author: Gabriel Rüeck
Delay Propagation in a Parallel Task Chain
Problem Statement
Similar to the last blog, we now want to examine how delays in parallel tasks propagate if we have a discrete and non-binary probabilistic pattern of delay for each involved task. We will assume to have reached our milestone if each task has been completed. We take the same example tasks as yesterday, but now, they are in parallel:

Source Data
In our example, we have 3 tasks, named “A”, “B” and “C”, and their respective durations is distributed according to the table and the graph below:
| Duration | 0 d | 1 d | 2 d | 3 d | 4 d | 5 d | 6 d | 7 d | 8 d | 9 d | 10 d | 11 d | 12 d | 13 d | 14 d | 15 d | 16 d | 17 d | 18 d | 19 d | 20 d | |
| A | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 5% | 10% | 25% | 20% | 15% | 10% | 10% | 5% | 0% | 0% | 100% |
| B | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 40% | 30% | 20% | 10% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 100% |
| C | 0% | 0% | 0% | 0% | 0% | 0% | 50% | 50% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 100% |
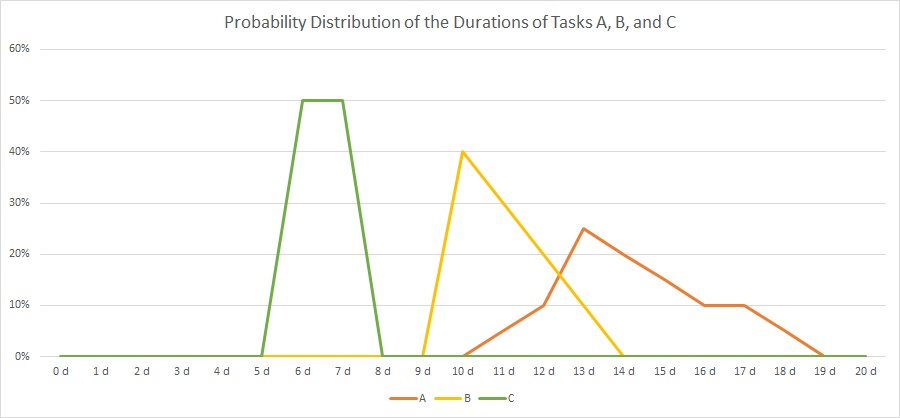 As you can see, there is not a fixed duration for each task as we have that in traditional project management. Rather than that, there are several possible outcomes for each task with respect to the real duration, and the probability of the outcome is distributed as in the graph above. The area below each graph will sum up to 1 (100%) for each task.
As you can see, there is not a fixed duration for each task as we have that in traditional project management. Rather than that, there are several possible outcomes for each task with respect to the real duration, and the probability of the outcome is distributed as in the graph above. The area below each graph will sum up to 1 (100%) for each task.
If we assume these distributions, how does the probability distribution of our milestone outcome look like?
Solution
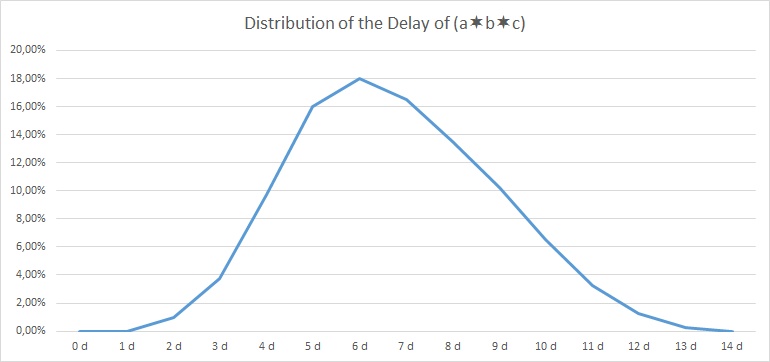
If we consider our milestone to be reached when all tasks have been completed, that is, when A, B, and C have been completed, then it becomes obvious that the distribition of task C has no influence at all. Even after 8 days when C has been completed with 100% certainty, there is no chance that either A or B will have started ever. The earliest day when our milestone could happen is on day 11 because this is the first day when there is a slight chance that A could be completed.
On the other side, on day 19, all tasks have been completed with 100% certainty, and hence by then, the milestone will have been reached for sure.
The correct mathematical approach in order to compute the resulting distribution is, for 2 tasks:
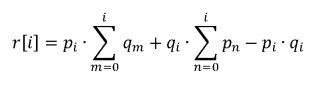
In order to facilitate our work and enable us to compute many parallel tasks, we use a C program named parallel.c which processes an input file of probability distributions in a certain format:
- Each description of a probability distribution of a task begins with a statement named # START
- Each description of a probability distribution of a task ends with a statement named # STOP
- Lines with comments must start with a #
- Empty lines are ignored.
- Data lines have an integer value, at least one white space and then a probability. This format can also be used for visualizations with gnuplot.
- The sum of probabilities for each task must add up to 1.00 (= 100%).
- Probability distributions for several tasks can be combined in one input file.
- The output file which the C file parallel.c will generate has the same syntax and can therefore be used as input file for further calculations.
The program parallel.c will compute 2 input vectors at a time and then use the result cor computation with the third, fourth, etc. input vector.
In the example, we use the input:
# START
11 0.05
12 0.10
13 0.25
14 0.20
15 0.15
16 0.10
17 0.10
18 0.05
# STOP
10 0.40
11 0.30
12 0.20
13 0.10
# STOP
6 0.50
7 0.50
# STOP
# The resulting vector is of size: 19
# START
0 0.0000
1 0.0000
2 0.0000
3 0.0000
4 0.0000
5 0.0000
6 0.0000
7 0.0000
8 0.0000
9 0.0000
10 0.0000
11 0.0350
12 0.1000
13 0.2650
14 0.2000
15 0.1500
16 0.1000
17 0.1000
18 0.0500
# STOP
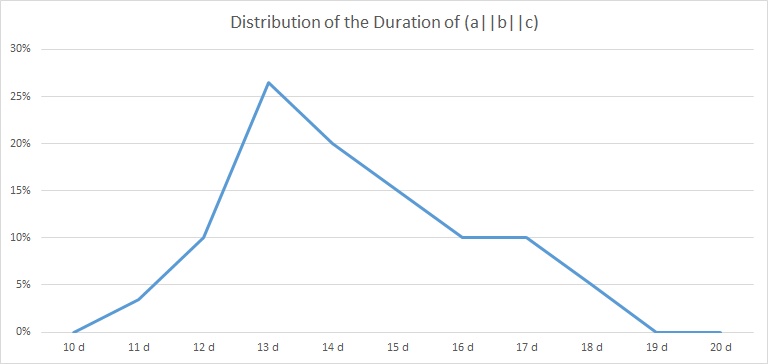
which is shown in the table and the graph below:
| Duration | 10 d | 11 d | 12 d | 13 d | 14 d | 15 d | 16 d | 17 d | 18 d | 19 d | 20 d | |
| (a||b||c) | 0,00% | 3,50% | 10,00% | 26,50% | 20,00% | 15,00% | 10,00% | 10,00% | 5,00% | 0,00% | 0,00% | 100% |
Downloads and Hints
- You can download the source code of parallel.c from https://caipirinha.spdns.org/~gabriel/Blog/parallel.c. The source code is in Unix format, hence no CR/LF, but only LF. It can be compiled with gcc -o {target_name} parallel.c. The C program is a demonstration only; no responsibility is assumed for damages resulting from its usage. It contains, however, already an optimization for the computational effort.
- The sample input file is available at https://caipirinha.spdns.org/~gabriel/Blog/input_parallel.dat and can be read with a standard text editor. If is also in Unix format (only LF).
- The maximum length of the output vector is of size 100.
Delay Propagation in Sequential Task Chains
Problem Statement
Today, we want to examine how delays in sequential tasks propagate if we have a discrete and non-binary probabilistic pattern of delay for each involved task. That sounds quite complicated, but such problem statements do exist in real life. Let’s look into the source data…

Source Data
In our example, we have 3 tasks, named “A”, “B” and “C”, and their respective durations is distributed according to the table and the graph below:
| Duration | 0 d | 1 d | 2 d | 3 d | 4 d | 5 d | 6 d | 7 d | 8 d | 9 d | 10 d | 11 d | 12 d | 13 d | 14 d | 15 d | 16 d | 17 d | 18 d | 19 d | 20 d | |
| A | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 5% | 10% | 25% | 20% | 15% | 10% | 10% | 5% | 0% | 0% | 100% |
| B | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 40% | 30% | 20% | 10% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 100% |
| C | 0% | 0% | 0% | 0% | 0% | 0% | 50% | 50% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 100% |
As you can see, there is not a fixed duration for each task as we have that in traditional project management. Rather than that, there are several possible outcomes for each task with respect to the real duration, and the probability of the outcome is distributed as in the graph above. The area below each graph will sum up to 1 (100%) for each task.
If we assume these distributions, how does the probability distribution of sequence of tasks A, B, C look like?
Solution
Level the durations
In a first approach, we define a minimum duration for each tasks. This is not mandatory, but it helps us to reduce the memory demand in our algorithm that we will use in a later stage. While we can define any minimum duration from zero to the first non-zero value of the probability distribution, we set them in our example to:
- A: tmin = 10 days
- B: tmin = 10 days
- C: tmin = 5 days (Keep in mind that here, we could also have selected 6 days, for example.)
That approach simply serves to level out tasks with large differences in their minimum duration, it is not necessary for the solution that is described below.
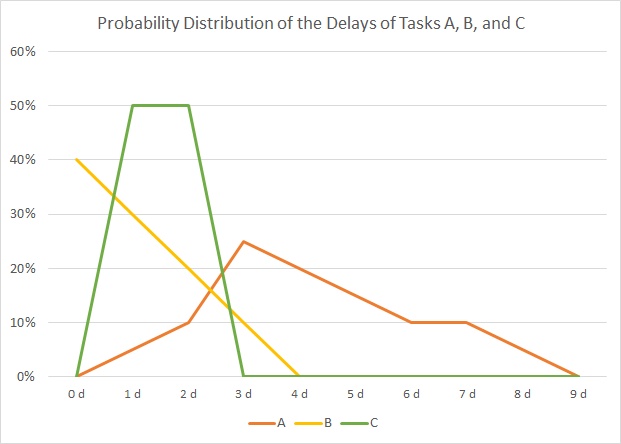
If we do so, then our overall minimum duration is 25 days then which we shall keep in mind right now. We now subtract the minimum duration from each task and get the values in the table and the graph below:
| Delay | 0 d | 1 d | 2 d | 3 d | 4 d | 5 d | 6 d | 7 d | 8 d | 9 d | |
| A | 0% | 5% | 10% | 25% | 20% | 15% | 10% | 10% | 5% | 0% | 100% |
| B | 40% | 30% | 20% | 10% | 0% | 0% | 0% | 0% | 0% | 0% | 100% |
| C | 0% | 50% | 50% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 100% |
Discrete Convolution
In order to compute the resulting probability distribution, we use the discrete convolution of the probability distributions of tasks A, B, and C, that is: (a∗b∗c). As the discrete convolution is computed as a sum of multiplications, we actually first compute (a∗b) and then convolute the result with c, that is we do ((a∗b)∗c). In order to facilitate our work and enable us to compute sequences of many tasks, we use a C program named faltung.c which processes an input file of probability distributions in a certain format:
- Each description of a probability distribution of a task begins with a statement named # START
- Each description of a probability distribution of a task ends with a statement named # STOP
- Lines with comments must start with a #
- Empty lines are ignored.
- Data lines have an integer value, at least one white space and then a probability. This format can also be used for visualizations with gnuplot.
- The sum of probabilities for each task must add up to 1.00 (= 100%).
- Probability distributions for several tasks can be combined in one input file.
- The output file which the C file faltung.c will generate has the same syntax and can therefore be used as input file for further calculations.
In the example, we use the input:
# START
0 0.00
1 0.05
2 0.10
3 0.25
4 0.20
5 0.15
6 0.10
7 0.10
8 0.05
# STOP
0 0.40
1 0.30
2 0.20
3 0.10
# STOP
0 0.00
1 0.50
2 0.50
# STOP
and get the following result:
# The resulting vector is of size: 14
# START
0 0.0000
1 0.0000
2 0.0100
3 0.0375
4 0.0975
5 0.1600
6 0.1800
7 0.1650
8 0.1350
9 0.1025
10 0.0650
11 0.0325
12 0.0125
13 0.0025
# STOP
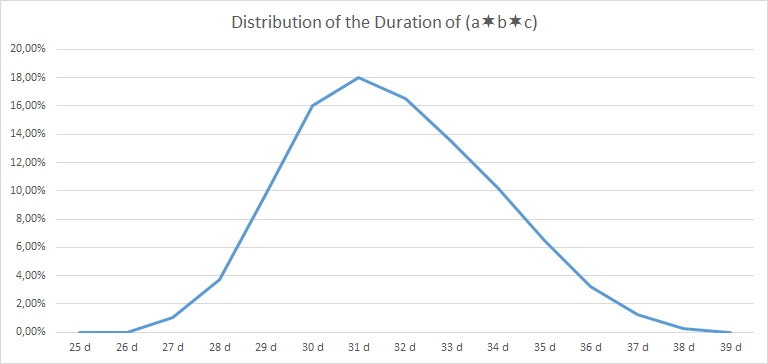
| Delay | 0 d | 1 d | 2 d | 3 d | 4 d | 5 d | 6 d | 7 d | 8 d | 9 d | 10 d | 11 d | 12 d | 13 d | 14 d | |
| (a∗b∗c) | 0,00% | 0,00% | 1,00% | 3,75% | 9,75% | 16,00% | 18,00% | 16,50% | 13,50% | 10,25% | 6,50% | 3,25% | 1,25% | 0,25% | 0,00% | 100% |
Downloads and Hints
- You can download the source code of faltung.c from https://caipirinha.spdns.org/~gabriel/Blog/faltung.c. The source code is in Unix format, hence no CR/LF, but only LF. It can be compiled with gcc -o {target_name} faltung.c. The C program is a demonstration only; no responsibility is assumed for damages resulting from its usage.
- The sample input file is available at https://caipirinha.spdns.org/~gabriel/Blog/input_faltung.dat and can be read with a standard text editor. If is also in Unix format (only LF).
- The maximum delay of the output vector is 99.
Sensitivity Analysis for Business Cases
Sensitivity Analysis
-
sales price
-
sales numbers
-
material cost
-
development cost
1-Dimensional Sensitivity Analysis

From the graph shown above, we can already get some important insights with respect to our example business case:
- The sales price has the largest influence on the resulting NPV. If sales prices drop by 5% only, our project does not add any more value to the business. Therefore, we must make sure that:
- our estimation of the sales price is as good as possible and not “inflated”
- we develop suitable countermeasures in case the sales price drops in the market
- The sales numbers and the development cost have less influence on the NPV; hence they are not our first concern.
2-Dimensional Sensitivity Analysis
Now, we will change two input variables at a time and leave the others constant (ceteris paribus). The tables for these investigations are listed on the sheet Scenario Analysis (2D). In additional to the overall monetary values of the NPV, the relative increments and decrements in % have been listed in tables on the right side of the respective scenario. I tried to visualize the result in Excel, but I found the related Excel graphics not very adequate. With the open-source tool gnuplot, it is however possible to create meaningful graphs. I am a novice with this tool and certainly, more elaborate visualizations are possible. Nevertheless, for a first interpretation, heat maps and contour lines serve the purpose. In order to create them, I had to transpose the tables into formats as shown on the sheet Scenario Analysis (2D), gnuplot. Furthermore, I had to use the setup commands listed on the sheet Init gnuplot in order to make gnuplot output the graphs below.

The graphs show heat maps with contour lines, and I believe that this is a good visualization for a 2-D sensitivity analysis although initially, it might take a while to familiarize yourself with this kind of visualization. The areas with green colour represent areas in which the NPV is better than in our base estimation, the areas with red colour represent areas in which the NPV is worse than in our initial base estimation. Each graph also has a contour lines which is labeled “0” in the legend, and this contour line represents combinations of the input variables where the NPV is the same than in our base estimation.
From the tables on the sheet Scenario Analysis (2D) and the graphs, we can get additional insight which is not accessible in the 1-D sensitivity analysis. We can draw the following conclusions, for example:
- If an increase in the sales price leads to a drop of the sales numbers of less than 15%, we still get a higher NPV than in our base estimation. If the price elasticity of our product warrants that move, then we should definitively go for it!
- If the development of additional features can yield a 10% increase of the sales price, we can easily spend 30% more development budget on those features.
- We can easily spend 25% more development budget if that additional development effort results in a 10% lower material cost.
3-Dimensional Sensitivity Analysis
I expect that with virtual reality gear like Oculus Rift, we might very soon be able to move ahead and create a visualization like a room that is filled with a coloured gas. By moving through that room and moving you head in the vertical, you might be able to explore that room in three dimensions. Similarly to the added insight that we gained while moving from a 1-D sensitivity analysis to a 2-D sensitivity analysis, we might find yet more additional insight.
Outlook
Clearly, heat maps with contour lines offer valuable insight in business cases, especially if we limit the heat maps to visualizations of those input variables that have proven to have the largest impact in the 1-D sensitivity analysis. In our business case example, the underlying formula for the NPV is simple which is reflected in the slightly curved or straight contour lines of the graphs. In more complicated business cases or in different applications, we might expect different and non-linear behaviours that then would result in more complicated heat maps and contour lines. We might find, for example that there can be a local minimum (a red-coloured spot) in our heat map which would then mean that we have a found a combination of our input variables that we must avoid under all circumstances, similar to a cliff in the ocean where we have to ship around. This would be visible immediately in the heat map. However, mathematically, we can even find such “cliffs” in an n-dimensional sensitivity analysis using multi-variable calculus although we are not able to “visualize” that in our mind. Such approaches might delivers us insight into dangerous or unfortunate combinations of input variables that other methods might not offer.
Sources
Admin-Skripte
Auf dieser Seite gibt es verschiedene Skripte, welche ich auf dem Caipirinha-Server einsetze, um anfallende Verwaltungsaufgaben zu lösen. Diese Skripte sollen als Anregung zur Erstellung eigener Skripte dienen, können aber natürlich auch komplett übernommen und bei Bedarf angepasst werden. Es finden sich hier:
Nach dem Booten
Dieses Skript führe ich als root nach einem Booten der Maschine durch. Es macht folgende Dinge:
- Das Akustik-Management der Festplatten wird auf “Performance” gestellt (sprich: “Geschwindigkeit” statt “Ruhe”).
- Für einige Festplatten wird ein automatischer Ruhezustand eingestellt. Die Systemplatten sollen aber nicht abschalten (Dauerbetrieb).
- Die Festplatten mit Videos (/home/public/Video) wird eingebunden. Dies erfolgt nicht gleich beim Start, weil diese Platte in die verschlüsselte Partition /home/public eingebunden wird.
- Der snmp– und der snmptrap-Dienst wird gestartet. Der snmp-Dienst wird erst nach dem Einbinden der Video-Festplatten gestartet, weil snmp auch die Plattenauslastung überwachen soll, und erst nach dem Einbinden der Video-Festplatten alle snmp-Variablen verfügbar sind.
- mrtg wird gestartet, um Netzwerk-Verkehr und CPU-Auslastung zu überwachen.
- Der sensor-Dienst wird gestartet, um die Temperatur im Server zu überwachen.
- Ein VLC-Server mit Telnet-Interface wird für die Caipithek gestartet. Dabei muss natürlich geheimes_passwort durch ein selbst gewähltes, geheimes Passwort ersetzt werden.
- Ein DLNA-Server wird mit dem Programm minidlna gestartet.
- openVPN wird gestartet und gleich danach noch MySQL. Der Grund dafür ist, dass der MySQL-Server auf dem Caipirinha-Server als Slave Server des MySQL-Servers auf rueeck.name läuft, und die Verbindung über openVPN getunnelt wird.
#! /bin/bash # # This script contains some commands that shall be executed after the # caipirinha server has booted up. # # Gabriel Rüeck 13.09.2010 # # Configure power and acustic management of the hard disks. hdparm -S 0 /dev/sda hdparm -S 0 /dev/sdb hdparm -S 180 /dev/sdc hdparm -S 180 /dev/sdd hdparm -S 180 /dev/sde hdparm -M 254 /dev/sda hdparm -M 254 /dev/sdb hdparm -M 254 /dev/sdc hdparm -M 254 /dev/sdd hdparm -M 254 /dev/sde # Mount Video Array mount /dev/md3 /home/public/Video # Start SNMP Services (must only be started after mounting /home/public/Video) /etc/init.d/snmpd start snmptrapd # Start mrtg touch /var/log/mrtg.log /var/run/mrtg.pid chown wwwrun:www /var/log/mrtg.log /var/run/mrtg.pid env LANG=C mrtg --user wwwrun --group www --logging /var/log/mrtg.log --lock-file /var/tmp/mrtg --pid-file=/var/run/mrtg.pid /etc/mrtg.conf # Start the sensor daemon rm /var/log/sensord.rrd 2>/dev/null modprobe coretemp it87 sensord -r /var/log/sensord.rrd -p /var/run/sensord.pid chmod a+r /var/log/sensord.rrd # Start cvlc for the Caipithek su -l wwwrun -c 'rm c*.log; cvlc -I oldtelnet --telnet-password geheimes_passwort > cvlc.log 2>&1 &' # Start DLNA Server (minidlna) su -l wwwrun -c '/usr/sbin/minidlna' # Start openVPN and mysql /etc/init.d/openvpn start /etc/init.d/mysql start
Wahrscheinlich könnte man dieses Skript auch automatisch nach dem Abschluss des Boot-Vorgangs ausführen lassen. Falls jemand eine entsprechende Idee hat, bin ich für Hinweise dankbar.
Neue Dateien auflisten lassen
Da verschiedene Benutzer des Caipirinha-Servers Schreibberechtigung auf dessen öffentliche Ordner haben, verliere ich oft selbst den Überblick darüber, welche Dateien wo neu abgelegt sind. Außerdem ist es schwierig, andere Benutzer über neu abgelegte Dateien zu informieren. Das soll nun das folgende Skript machen, welches einen RSS-Feed erzeugt, der dann mit modernen Browsern oder Mail-Clients oder RSS-Clients lesbar ist. Über einen cron-Job wird dieses Skript einmal pro Nacht ausgeführt und erzeugt dann einen neuen RSS-Feed, den andere Benutzer einbinden können. Was ein RSS-Feed ist und wie er aufgebaut ist, wird auf [1] beschrieben.
update_rss.sh:
#!/bin/bash
#
# This script searches various folders for new files, extracts a description of the files and generates an RSS 2.0 feed in XML.
#
# Gabriel Rüeck, gabriel@caipirinha.homelinux.org, 10.10.2012
#
# Pre-define some variables and read the configuration files.
umask 0022
readonly GENERATOR='Caipirinha RSS Generator'
readonly CONFIGPATH='/etc/rss'
DURATION=7
CHANNEL_NAME=$(hostname)
CHANNEL_LINK="http://$(hostname --fqdn)/"
TMPFILE='/tmp/rss'$RANDOM
# Add the PATH variable so that it is the same whether the program is called from the shell or from within the cron environment.
PATH='/usr/bin:/bin:/opt/gnome/bin'
# Get additional options, if available
while getopts :D:o:p:t:T: OPT
do case "$OPT" in
"D") OPT_DESCRIPTION=$OPTARG;;
"o") if [ ! -f $OPTARG ]; then
echo -e "ERROR: The configuration file \""$OPTARG"\" does not exist.\n"
exit 2
else
CONFIGFILE=$OPTARG
fi;;
"p") OPT_PATHFILE=$OPTARG;;
"t") OPT_DURATION=$OPTARG;;
"T") OPT_TITLE=$OPTARG;;
esac
done
# Read the configuration file. If no configuration file has been specified, try to read "/etc/rss/rss.conf".
# However, there will not be an error message if no configuration file is available.
test -e ${CONFIGFILE:=$CONFIGPATH'/rss.conf'} && . $CONFIGFILE
# Process optional arguments; they have precedence over the values defined in the configuration files.
test -n "$OPT_DESCRIPTION" && DESCRIPTION=$OPT_DESCRIPTION
test -n "$OPT_DURATION" && DURATION=$OPT_DURATION
test -n "$OPT_PATHFILE" && PATH_FILE=$OPT_PATHFILE
test -n "$OPT_TITLE" && TITLE=$OPT_TITLE
# Check if sufficient arguments have been provided.
shift $[$OPTIND-1]
if [ $# -lt 1 ]; then
echo -e "Usage: "$0" [OPTIONS] DST_FILE_1 [DST_FILE_2 [...]]\n"
exit 1
fi
# Check if PATH_FILE exists.
if [ ! -f $PATH_FILE ]; then
echo -e "ERROR: The path file \""$PATH_FILE"\" does not exist.\n"
exit 2
fi
# Get the lower link bar which has links to all subfolders that are available on the server.
# As the pipe (|) creates a subshell, the while loop has to be located in () and has to have an echo command at the end which will then
# send the accumulated variable back to the calling shell. That may look strange, but otherwise, things will not work... Bad trap for newbies...
# Create a footer that contains links to all folders that shall be searched, with some CSS-style formatting, actuallz oriented towards www.faz.net
FINAL='<div style="margin:5px 0 5px 0; border-top:1px solid blue; font:9px arial;"><a href="'$CHANNEL_LINK'">'$CHANNEL_NAME'</a> '\
$(sed '/^ *#.*/d' $PATH_FILE | (while read LINE;
do HTML_PATH=$(echo $LINE | cut -f2 -d"|")
DESCRIPTION=$(echo $LINE | cut -f3 -d"|")
FINAL=$FINAL'| <a href="'$HTML_PATH/'">'$DESCRIPTION'</a> '
done;
echo $FINAL;))'</div>'
# Make the file readable for everyone
umask 022
# Create page headers for the RSS file
echo '<?xml version="1.0" encoding="UTF-8"?>' > $TMPFILE
echo '<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom">' >> $TMPFILE
echo '<channel>' >> $TMPFILE
echo " <title>$TITLE</title>" >> $TMPFILE
echo " <link>$CHANNEL_LINK</link>" >> $TMPFILE
echo " <description>$DESCRIPTION</description>" >> $TMPFILE
echo " <managingEditor>$EDITOR</managingEditor>" >> $TMPFILE
echo " <generator>$GENERATOR</generator>" >> $TMPFILE
echo ' <pubDate>'$(date -R)'</pubDate>' >> $TMPFILE
# Put an image of the server on the headline.
echo ' <image>' >> $TMPFILE
echo " <title>$TITLE</title>" >> $TMPFILE
echo " <url>$IMG_URL</url>" >> $TMPFILE
echo " <link>$CHANNEL_LINK</link>" >> $TMPFILE
echo ' </image>' >> $TMPFILE
# Scan all folders on whether there are new files. Extract the file name, create a link on it, get a description of the file, the date of the
# last modification, and extract an icon from the Apache2 icons.
sed '/^ *#.*/d' $PATH_FILE | while read LINE;
do SEARCH_PATH=$(echo $LINE | cut -f1 -d"|")
HTML_PATH=$(echo $LINE | cut -f2 -d"|")
OMIT_PATH=$(echo $LINE | cut -f4 -d"|")
# The "cd" command must be connected with the "find" command because otherwise, if the "cd" path did not exist, the script would search the entire users's home
# directory and deliver sensitive information with the file names listed.
cd "$SEARCH_PATH" && find -L -not -path "$OMIT_PATH" -type f -mtime -$DURATION -perm -004 -name "[[:alnum:]]*" -not -name "*~" -not -name "*.old" -not -name "metadata.xml" -not -path "*/\.*" -print 2>/dev/null |
# The following commands will be executed in a subshell; they would anyway because they follow the pipe (|) symbol.
# But first the variable IFS is set to "|" as separator. Normally, IFS is set to " ". This is important for the read command as IFS
# contains the character that is used as a separator for the read command. A " " as separator leads to problems when the file name has
# a double white space like " " or so in the name as read would report this back as a single white space " ". That !$#% cost me a day...
(OLD_IFS=$IFS
IFS=""
while read -r NAME;
do LINK_NAME=$(echo $NAME | sed -f $CONFIGPATH/link_name.sed)
HTML_NAME=$(basename $NAME | sed -f $CONFIGPATH/html_name.sed)
FILE_TYPE_KNOWN=false
# Try first to determine the file type with the "file" command as sometimes, this yields the more exact result.
FILE_TYPE=$(file -b $NAME)
case "$FILE_TYPE" in
"ASCII text") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/txt.png"> '; FILE_TYPE_KNOWN=true;;
*"perl script"*) FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/source_pl.png"> '; FILE_TYPE_KNOWN=true;;
*"shell script"*) FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/shellscript.png"> '; FILE_TYPE_KNOWN=true;;
"vCard"*) FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/vcalendar.png"> '; FILE_TYPE_KNOWN=true;;
esac
if ! $FILE_TYPE_KNOWN; then
# If the file type could not be determined with the "file" command, then proceed with "gnomeinfo-vfs".
FILE_TYPE=$(gnomevfs-info $NAME | sed -n 's/\(^MIME type *:\) \(.*\)/\2/p')
# unset $FILE_DESC because there may be old content in it.
unset FILE_DESC
case "$FILE_TYPE" in
"application/msaccess") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/database.png"> ';;
"application/msword") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/wordprocessing.png"> ';;
"application/octet-stream") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/binary.png"> ';;
"application/pdf") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/pdf.png"> ';;
"application/rtf") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/document.png"> ';;
"application/vnd.ms-excel") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/spreadsheet.png"> ';;
"application/vnd.ms-outlook") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/message.png"> ';;
"application/vnd.ms-project") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/txt2.png"> ';;
"application/vnd.ms-powerpoint") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/presentation.png"> ';;
"application/vnd.openxmlformats-officedocument.presentation"*) FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/presentation.png"> ';;
"application/vnd.openxmlformats-officedocument.spreadsheet"*) FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/spreadsheet.png"> ';;
"application/vnd.openxmlformats-officedocument.wordprocessing"*) FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/wordprocessing.png"> ';;
"application/vnd.oasis.opendocument.spreadsheet") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/spreadsheet.png"> ';;
"application/vnd.oasis.opendocument.text") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/wordprocessing.png"> ';;
"application/x-bittorrent") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/torrent.png"> ';;
"application/x-cd-image") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/cdimage.png"> ';;
"application/x-compressed-tar") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/tgz.png"> ';;
"application/x-font-speedo") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/font.png"> ';;
"application/x-font-ttf") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/font_truetype.png"> ';;
"application/x-font-type1") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/font_type1.png"> ';;
"application/x-java-archive") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/source_java.png"> ';;
"application/x-ms-dos-executable") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/binary.png"> ';;
"application/x-msi") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/make.png"> ';;
"application/x-rpm") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/rpm.png"> ';;
"application/x-subrip") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/txt2.png"> ';;
"application/x-509"*) FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/encrypted.png"> ';;
"application/xml") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/html.png"> ';;
"application/zip") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/zip.png"> ';;
"audio/midi") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/midi.png"> ';;
"audio/"*) FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/sound.png"> ';;
"image/"*) FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/image.png"> ';;
"text/calendar") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/vcalendar.png"> ';;
"text/csv") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/spreadsheet.png"> ';;
"text/html") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/html.png"> ';;
"text/plain") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/txt.png"> ';;
"text/x-chdr") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/source_h.png"> ';;
"text/x-c++hdr") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/source_h.png"> ';;
"text/x-csrc") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/source_c.png"> ';;
"text/x-c++src") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/source_c.png"> ';;
"text/x-log") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/widget_doc.png"> ';;
"text/x-uri") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/html.png"> ';;
"video/quicktime") FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/quicktime.png"> ';;
"video/mp"*) FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/video.png"> ';;
"video/x-"*) FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/video.png"> ';;
*) FILE_DESC='<img src="'${CHANNEL_LINK}'kde-icons/unknown.png"> ';;
esac
fi
# Add the file description to the selected image.
if [ ${FILE_TYPE%%/*} = "audio" ]; then
DATA=$(mediainfo -f "$NAME")
MEDIA_DURATION=$(echo $DATA | sed -n 's/^Duration[^:]*:[^0-9]*\([0-9].*[^0-9].*\)/\1/p' | head -n1)
FILE_DESC="$FILE_DESC $FILE_TYPE $MEDIA_DURATION, "$(stat -c%s" Bytes" $NAME)
elif [ ${FILE_TYPE%%/*} = "video" ]; then
DATA=$(mediainfo -f "$NAME")
MEDIA_WIDTH=$(echo $DATA | sed -n 's/^Width[^:]*:[^0-9]*\([0-9].*\)/\1/p' | head -n1)
MEDIA_HEIGHT=$(echo $DATA | sed -n 's/^Height[^:]*:[^0-9]*\([0-9].*\)/\1/p' | head -n1)
MEDIA_DURATION=$(echo $DATA | sed -n 's/^Duration[^:]*:[^0-9]*\([0-9].*[^0-9].*\)/\1/p' | head -n1)
VIDEO_STREAMS=$(echo $DATA | sed -n 's/^Count of video streams[^:]*:[^0-9]*\([0-9].*\)/\1/p' | head -n1)
AUDIO_STREAMS=$(echo $DATA | sed -n 's/^Count of audio streams[^:]*:[^0-9]*\([0-9].*\)/\1/p' | head -n1)
FILE_DESC="$FILE_DESC $FILE_TYPE ${MEDIA_WIDTH}x${MEDIA_HEIGHT}, $MEDIA_DURATION, $VIDEO_STREAMS video streams, $AUDIO_STREAMS audio streams, "$(stat -c%s" Bytes" $NAME)
else
FILE_DESC="$FILE_DESC $FILE_TYPE, "$(stat -c%s" Bytes" $NAME)
fi
# Create a new item for each newly found file.
echo ' <item>' >> $TMPFILE
echo ' <title>'$HTML_NAME'</title>' >> $TMPFILE
echo ' <link>'$HTML_PATH/$LINK_NAME'</link>' >> $TMPFILE
echo ' <pubDate>'$(date -Rr $NAME)'</pubDate>' >> $TMPFILE
echo ' <description>'$FILE_DESC$FINAL'</description>' >> $TMPFILE
echo ' <guid>'$HTML_PATH/$LINK_NAME'</guid>' >> $TMPFILE
echo ' </item>' >> $TMPFILE
done;
# Reset IFS to its old value
IFS=$OLD_IFS)
done;
echo '</channel>' >> $TMPFILE
echo '</rss>' >> $TMPFILE
# Move the file from the TMP folder to the final destinations.
for i in $*; do
cp $TMPFILE $i
done
rm $TMPFILE
Leider funktioniert dieses Skript nicht ganz allein, sondern benötigt noch mehrere Hilfsdateien, was die Anwendung erschwert. In /etc/rss sollten folgende vier Dateien abgelegt werden:
- /etc/rss/link_name.sed
- /etc/rss/html_name.sed
- /etc/rss/rss.conf
Die sed-Hilfsdateien werden im Browser leider nicht richtig wieder gegeben. Deshalb kann man sie als Archiv unter [2] herunter laden. Sie werden für die sed-Aufrufe im Skript benötigt.
Die vierte Hilfsdatei ist hier abgedruckt:
/etc/rss/rss.conf:
# CONFIGURATION FILE FOR THE RSS SCRIPT # This File will be read by the RSS script. The settings in this file are the general settings for the script. # # General Settings for the RSS Script # TITLE="New Files on CAIPIRINHA" CHANNEL_NAME="CAIPIRINHA Server" CHANNEL_LINK="http://caipirinha.homelinux.org/" DESCRIPTION="Photographs, Music, Books and other Documents" EDITOR="gabriel@caipirinha.homelinux.org (Gabriel Rüeck)" # # Settings for the Image of the Website # IMG_URL="http://caipirinha.homelinux.org/jpg/Caipirinha.jpg" # # Settings for the Path File (containing all paths that shall be searched and their respective HTML links) PATH_FILE="/home/public/paths.txt" # # Miscellaneous Settings # # Duration sets the number of days for the "find" command. Files which were modified up to $DURATION days, will be # taken into account. # DURATION=30
Die ersten beiden Dateien beschreiben Ersetzungen, welche das mehrfach eingesetzte sed-Kommando im Skript vornehmen soll. Ein RSS-Feed ist ja eine XML-Datei, und deshalb müssen bei den auf dem Caipirinha-Server vorkommenden Dateinamen, welche ja im Idealfall beliebige Zeichen enthalten dürfen, zahlreiche Ersetzungen vorgenommen werden, um den Eigenheiten von XML und HTML gerecht zu werden.
Die dritte Datei ist eine Standardkonfiguration, welche verschiedene Parameter des RSS-Feeds (beispielsweise den Link zum Piktogramm des RSS-Feeds) festlegt. Alle in dieser Standard-Konfiguration angegebenen Werte können aber auch durch eine eigene Konfigurationsdatei überschrieben werden. Eine solche modifizierte Konfigurationsdatei ist hier abgedruckt:
Eigene Konfigurationsdatei:
# CONFIGURATION FILE FOR THE RSS SCRIPT # This File will be read by the RSS script. The settings in this file are the general settings for the script. # # General Settings for the RSS Script # TITLE="Gabriel Rüeck" CHANNEL_NAME="Gabriel Rüeck" CHANNEL_LINK="http://caipirinha.homelinux.org/~gabriel/" DESCRIPTION="News from Gabriel Rüeck" EDITOR="gabriel@caipirinha.homelinux.org (Gabriel Rüeck)" # # Settings for the Image of the Website # IMG_URL="http://caipirinha.homelinux.org/~gabriel/Bilder/Zeitung.jpg" # # Settings for the Path File (containing all paths that shall be searched and their respective HTML links) PATH_FILE="/home/gabriel/rss/paths.txt" # # Miscellaneous Settings # # Duration sets the number of days for the "find" command. Files which were modified up to $DURATION days, will be # taken into account. # DURATION=30
Wichtig ist bei eigenen Konfigurationsdateien nur, dass die entsprechenden Schlüsselworte genau so geschrieben werden wie in der allgemeinen Konfigurationsdatei /etc/rss/rss.conf. Abgesehen von einer eigenen Konfigurationsdatei kann man aber auch dediziert eigene Optionen beim Aufruf des Skripts angeben. Folgende Optionen sind möglich:
- -D Beschreibung definiert die Beschreibung des RSS-Feeds.
- -o Dateiname gibt an, wo sich die zu verwendende Konfigurationsdatei befindet. Der Default-Wert ist /etc/rss/rss.conf.
- -p Dateiname gibt an, wo sich die Pfaddatei befindet, in welcher die zu durchsuchenden Verzeichnisse angegeben sind (siehe unten).
- -t Zeitdauer gibt an, wieviele Tage die zu berücksichtigenden Dateien (die in den RSS-Feed aufgenommen werden), alt sein dürfen.
- -T Titel definiert den Titel des RSS-Feeds.
Die dediziert angegebenen Optionen haben Vorrang gegenüber den Optionen in einer angegebenen Konfigurationsdatei. Eine mit -o angebene Konfigurationsdatei hat wiederum Vorrang gegenüber der allgemeinen Konfigurationsdatei /etc/rss/rss.conf.
Als letzte Datei in diesem Sammelsurium wird noch die üblicherweise in der Konfigurationsdatei referenzierte Pfaddatei benötigt. Ein Beispiel einer Pfaddatei ist hier gezeigt:
/home/public/paths.txt:
# Path List for the RSS Script # # This file contains the folders that will be scanned by the RSS script. # Each line contains three elements which have to be separated by a | character. The structure is: # # path_to_be_scanned | HTML_prefix | Title | Optional path which is to be omitted # # It is important that the HTML_prefix does not have a trailing / character. # /home/public/Bücher|https://caipirinha.homelinux.org/MM/Bücher|Books /home/public/Dokumente|https://caipirinha.homelinux.org/MM/Dokumente|Documents /home/public/Unterhaltung|https://caipirinha.homelinux.org/MM/Unterhaltung|Entertainment /home/public/Spiele|https://caipirinha.homelinux.org/MM/Spiele|Games /home/public/Linux|https://caipirinha.homelinux.org/MM/Linux|Linux /home/public/Video|https://caipirinha.homelinux.org/MM/Filme|Movies #/home/public/Video|https://caipirinha.homelinux.org/MM/Filme|Movies|./[[:digit:]]-* #/home/public/Audio|https://caipirinha.homelinux.org/MM/Musik|Music /home/public/Bilder|https://caipirinha.homelinux.org/MM/Fotos|Pictures /home/public/Software|https://caipirinha.homelinux.org/MM/Software|Windows

Wegen des Bash-Skriptes sind hier leider einige Eigenarten zu beachten:
- Jede gültige Zeile besteht aus drei Teilen: dem zu durchsuchenden Pfad ohne “/” am Ende, dem HTML-Link, unter dem dieses Verzeichnis zu finden ist und der Beschreibung, welche diesem Verzeichnis zuzuordnen ist
- Die letzte Zeile muss mit einem Zeilenendekennzeichen abgeschlossen werden, d.h. der Cursor muss beim Speichern in der letzten und leeren Zeile sein.
Bei der Konfiguration des Apache-Servers muss natürlich berücksichtigt werden, dass die einzelnen Verzeichnisse wie beispielsweise /home/public/Bücher dann auch über HTML unter https://caipirinha.homelinux.org/MM/Bücher zugänglich sind. Damit keine unbefugten Zugriffe stattfinden, empfehlen sich Zugangsbeschränkungen für den HTML-Zugriff.

Außerdem müssen die KDE-eigenen Piktogramme unter /opt/kde3/share/icons/crystalsvg/48×48/mimetypes unter dem Link http://caipirinha.homelinux.org/kde-icons zugänglich gemacht werden, denn das Skript bezieht sich auf dieses Verzeichnis, um Bilder in den RSS-Feed einzufügen. Allerdings wird das Auflisten der Piktogramme in diesem Webverzeichnis untersagt; es wird lediglich das Anzeigen eines dedizierten Piktogrammes gestattet, wenn man den vollen Dateinamen eingibt.
Das hier abgebildete Skript update_rss.sh funktioniert also nur dann richtig, wenn die zwei genannten sed-Skripte sowie mindestens eine gültige Konfigurationsdatei korrekt installiert sind. Wurde alles korrekt eingerichtet, dann kann man mit
./update_rss.sh /home/public/rss_index.xml
einen neuen RSS-Feed unter /home/public/rss_index.xml erzeugen lassen. Man kann übrigens anstatt einer Zieldatei für den RSS-Feed auch gleich mehrere Zieldateien angeben. Dann werden gleich mehrere identische Feeds in unterschiedlichen Verzeichnissen generiert.

Der Aufruf
./update_rss.sh -o $HOME/rss/rss.conf /home/public/rss_index.xml
liest noch die Konfigurationsdatei $HOME/rss/rss.conf, wertet diese aus und erzeugt dann den RSS-Feed /home/public/rss_index.xml.
Ich will nicht verschweigen, dass der erzeugte RSS-Feed nicht immer die RSS-Spezifikationen erfüllt. Dies hängt meist mit irgendwelchen Sonderzeichen im Dateinamen zusammen. Allerdings lässt sich der Feed in den meisten Browsern oder Mail-Clients ohne Probleme einbinden.
Doppelte Dateien löschen
In den Benutzerverzeichnissen auf dem Server tummeln sich oft Dateien, welche bereits in öffentlichen Ordnern des Servers existieren. Dadurch wird die gleiche Datei mehrfach auf dem Server abgelegt. Ein klarer Fall von Platzverschwendung. Das soll sich mit dem folgenden Skript ändern:
kill_doubles.sh:
#!/bin/bash
#
# This script performs the following steps:
# 1. Scan dedicated public folders and create MD5 hashes of all non-hidden files.
# 2. Save a list of these files with MD5 hashes.
# 3. Scan user folders and create MD5 hashes of all non-hidden files.
# 4. Compare these MD5 hashes with the ones in the public folders.
# 5. If a double file is detected, deöete the public file in the personal folder and replace it with a link
# to the respective file in the public folder.
#
# Gabriel Rüeck, gabriel@caipirinha.homelinux.org, 10.09.2008
# last update: 11.12.2011
#
# Pre-define some variables and read the configuration files.
readonly CHANGED_FILES='/tmp/changed_files.txt'
readonly CHECKSUM_FILE='/home/public/Prüfsummen.txt'
readonly GROUP='users'
readonly MAIL_RCPT='root@caipirinha'
readonly MAIL_SUBJ='Geänderte Benutzer-Dateien'
# Do not bother with small files.
readonly SIZE='+30k'
umask 022
# Scan dedicated public folders, create files with MD5 hashes in these folders and save the name of those files in another file named $CHECKSUM_LOCATIONS.
rm ${CHECKSUM_FILE} 2>/dev/null
for SCANPATH in /home/public/Audio /home/public/Bilder; do
find ${SCANPATH} -type f -size ${SIZE} -name "[[:alnum:]]*" -and -not -name "Thumbs.db*" -exec md5sum {} 2>/dev/null \; >> ${CHECKSUM_FILE}
done;
# Browse through all MD5 hashes listed in $CHECKSUM_FILE.
rm ${CHANGED_FILES} 2>/dev/null
# Browse through various folders
# Observe the [ABCDEFGHIJKLMNOPQRSTUVWXYZÄÖÜ] which is NOT equivalent to [A-ZÄÖÜ] under the locale de_DE.UTF-8, but only under the locale C.
for SCANPATH in /home/gabriel/[ABCDEFGHIJKLMNOPQRSTUVWXYZÄÖÜ]* \
/home/joselia/[ABCDEFGHIJKLMNOPQRSTUVWXYZÄÖÜ]*; do
# Extract user name.
USER=$(echo ${SCANPATH} | sed -n 's/^\/home\/\([^\/]*\).*/\1/p')
# Find all normal files starting with an alphanumeric name (skip .files).
find "${SCANPATH}" -not -path '*/.*' -type f -size ${SIZE} -exec md5sum {} 2>/dev/null \; |
(while read -r DATASET
do CHKSUM=$(echo "${DATASET}" | cut -c-32)
FILEPATH_IN_CHECK=$(echo "${DATASET}" | cut -c35-)
# Look for the first occurency of an identical checksum in $CHECKSUM_FILE.
RESULT=$(fgrep -m1 "${CHKSUM}" "${CHECKSUM_FILE}")
if [ -n "${RESULT}" ]; then
FILEPATH_REPLACE=$(echo "$RESULT" | cut -c35-)
# Check if the file that shall be linked to has a generic digikam file name. Those names are like:
# IMG_0000.JPG or P0000000.JPG
FNAME_IN_CHECK=${FILEPATH_IN_CHECK##*/}
PNAME_REPLACE=${FILEPATH_REPLACE%/*}"/"
FNAME_REPLACE=${FILEPATH_REPLACE##*/}
if [[ "${FNAME_REPLACE}" =~ ^[PI].*[0-9]\.JPG$ ]] && [ "${FNAME_IN_CHECK}" != "${FNAME_REPLACE}" ]; then
# Replace the generic digikam name by the file name of the respective user file.
echo "Umbenennung: ${FILEPATH_REPLACE} → ${PNAME_REPLACE}${FNAME_IN_CHECK}" >> ${CHANGED_FILES}
mv "${FILEPATH_REPLACE}" "${PNAME_REPLACE}${FNAME_IN_CHECK}"
# Update the variable $FILEPATH_REPLACE as the reference file has been renamed.
FILEPATH_REPLACE=${PNAME_REPLACE}${FNAME_IN_CHECK}
fi
# Write result into a tmp file.
echo "Link: ${FILEPATH_IN_CHECK} → ${FILEPATH_REPLACE}" >> ${CHANGED_FILES}
# Replace the examined file by a link to the existing file.
rm "${FILEPATH_IN_CHECK}"
ln -s "${FILEPATH_REPLACE}" "${FILEPATH_IN_CHECK}"
chown -h ${USER}:${GROUP} "${FILEPATH_IN_CHECK}"
fi
done)
done
# Send an email to $MAIL_RCPT if files have been replaced.
if [ -s "${CHANGED_FILES}" ]; then
cat ${CHANGED_FILES} | mail -s "${MAIL_SUBJ}" "${MAIL_RCPT}"
fi
In diesem Skript werden zunächst alle Dateien in den öffentlichen Verzeichnissen /home/public/Audio und /home/public/Bilder erfasst. Für jede Datei wird die MD5-Prüfsumme berechnet und in /home/public/Prüfsummen.txt abgelegt.
Dann werden zwei Benutzerverzeichnisse durchsucht, und für die dort gefundenen Dateien, welche größer als eine bestimmte, im Skript festgelegte Mindestgröße sind, wird ebenfalls die MD5-Prüfsumme berechnet. Das Skript vergleicht nun, ob eine solche Prüfsumme schon in der Datei /home/public/Prüfsummen.txt existiert. Wenn dem so ist, dann bedeutet dies, dass die gerade bearbeitete Datei schon auf dem Server existiert. In diesem Fall löscht das Skript die entsprechende Datei im Benutzerverzeichnis und ersetzt sie durch einen Link auf die jeweilige Datei in /home/public/Audio oder /home/public/Bilder. Da es sich bei den meisten mehrfach vorkommenden Dateien um Fotos handelt, prüft das Skript aber noch behelfsmäßig, ob die bereits existierende Datei einen generischen Namen hat, wie er von Digitalkameras kommt, also beispielsweise “P1234567.JPG” oder so. Diese Prüfung ist im hier abgedruckten Skript aber nicht vollkommen, sondern wird nur näherungsweise durchgeführt. Wenn also die bereits existierende Datei in /home/public/Audio oder /home/public/Bilder einen solchen generischen Namen trägt, im Benutzerverzeichnis aber schon umbenannt worden ist (z.B. weil der jeweilige Benutzer nun einen “richtigen” Namen vergeben hat), dann wird dieser Dateiname auch für die jeweilige Datei auf /home/public/Audio oder /home/public/Bilder übernommen, damit auch andere Benutzer wissen, worum es sich bei dem entsprechenden Foto handelt.
Zum Schluss verschickt das Skript dann noch eine Email, in der über die ersetzten und umbenannten Dateien berichtet wird.
Bluetooth-Infobox
Die Bluetooth-Infobox ist ein Skript, welches über einen Eintrag in der crontab die Umgebung nach Geräten mit Bluetooth scannt und dann versucht, Dateien über das OBEX Push-Protokoll an die gefundenen Geräte zu verschicken. Damit kann man eine Art Informations-Box aufbauen, die Dateien automatisch an Mobiltelefone in der näheren Umgebung verschickt. Auf einer Messe ist mir das selbst einmal passiert.
Dazu muss der Server natürlich mit einem USB-Dongle versehen werden. Auf meiner Maschine habe ich einen USB-Bluetooth-Adapter der Klasse 1 von DELOCK (DELOCK 61477) eingesetzt, mit dem ich gute Erfahrungen gemacht habe.
Weiterhin müssen über YaST folgende Software-Pakete installiert werden:
- bluez-libs
- bluez-utils
- libusb-devel
- openobex-devel
- yast2-bluetooth
Ferner muss noch das Programm ussp-push von Davide Libenzi compiliert und installiert werden. Die Beschreibung des Programmes und den Link zum Download gibt es auf [3]. Mit ussp-push kann man Dateien über das Object Push-Protokoll [4]
verschicken. Wenn man sich das Paket von Davide Libenzis Seite
herunterlädt, muss man es nur noch entpacken und dann das Programm
entsprechend der dem tar-Archiv beigefügten Anleitung compilieren. Dann
sollte man das daraus entstandene Programm an eine zentrale Stelle
kopieren, beispielsweise an /usr/sbin/ussp-push.
Jetzt schafft man sich in einem für alle zugänglichen Pfad ein neues Verzeichnis, beispielsweise:
drwxr-sr-x 4 nobody users 128 25. Sep 18:00 /home/public/Bluetooth-Infobox
Ich habe dieses Verzeichnis dem Benutzer nobody zugeordnet, weil das unten abgebildete Skript aus Sicherheitsgründen ebenfalls unter diesem Benutzer läuft. In disem Verzeichnis wird das Skript auch die Log-Dateien anlegen, welche die Ausgaben des ussp-push-Kommandos protokolliert. In diesem Verzeichnis müssen nun zwei Unterverzeichnisse mit entsprechenden Rechten angelegt werden, und zwar:
drwxr-sr-x 2 nobody users 128 26. Sep 21:13 /home/public/Bluetooth-Infobox/database drwxrwsr-x 2 nobody users 80 25. Sep 15:38 /home/public/Bluetooth-Infobox/outbox
Im Unterverzeichnis outbox können alle Benutzer der
Maschine beliebige Dateien ablegen, die dann an die Mobiltelefone
verschickt werden sollen, wenn das Skript abgearbeitet wird.
Im Unterverzeichnis database wird das Skript später eine
Art Datenbank anlegen, in welcher für jedes Mobiltelefon, an das
mindestens eine Datei erfolgreich verschickt worden ist, eine Datei
existiert, welche die Unix-Zeitstempel und den Namen der verschickten
Datei enthält.
Mit diesen Vorbereitungen kann man nun das eigentliche Skript bt_infobox.sh über einen Eintrag in der crontab von nobody aktivieren:
bt_infobox.sh:
#!/bin/bash
#
# Bluetooth Info Box
#
# This script searches for Bluetooth-enabled mobile phones in the proximity, registers their hardware address
# and looks whether there are any new files in the outbox that have not yet been sent to these mobile phones.
# It then sends the missing files to the mobile phones.
#
# Gabriel Rüeck, gabriel@caipirinha.homelinux.org, 25.09.2008
#
# Pre-define some variables and read the configuration files.
readonly WORKDIR='/home/public/Bluetooth-Infobox'
# Set the PATH variable and include /usr/sbin (where ussp-push has been put).
PATH='/usr/sbin:/usr/bin:/bin'
# Scan for Bluetooth-enabled phones in the proximity and extract their machine address.
# Check if a database file exists for the respective HW address.
# If that is the case, browse through all files in the outbox and see if they have already been sent to that phone.
# If they have not been sent to that phone, send them and write the file info into the database file.
# If no database file exists, send all files in the outbox to the phone and write the file info into the database file.
# The database file contains the timestamp and the name of the files that have been sent from the outbox to the respective phone.
hcitool scan | egrep -o '\b[0-9A-F]{2}:[0-9A-F]{2}:[0-9A-F]{2}:[0-9A-F]{2}:[0-9A-F]{2}:[0-9A-F]{2}\b' | \
while read HW_ADDRESS
do if [ -f "${WORKDIR}/database/${HW_ADDRESS}.txt" ]
then
cd "${WORKDIR}/outbox" && find . -maxdepth 1 -type f -print 2>/dev/null |
while read LOCAL_FNAME
do LONG_FNAME=$(stat -c '%Y %n' "${LOCAL_FNAME}")
if (! fgrep -q "${LONG_FNAME}" "${WORKDIR}/database/${HW_ADDRESS}.txt")
then REMOTE_FNAME=$(basename "${LOCAL_FNAME}")
ussp-push "${HW_ADDRESS}@" "${LOCAL_FNAME}" "${REMOTE_FNAME}" >> "${WORKDIR}/ussp-push.log" 2>&1 && (echo "${LONG_FNAME}" >> "${WORKDIR}/database/${HW_ADDRESS}.txt"; sleep 3s)
fi
done
else
cd "${WORKDIR}/outbox" && find . -maxdepth 1 -type f -print 2>/dev/null |
while read LOCAL_FNAME
do REMOTE_FNAME=$(basename "${LOCAL_FNAME}")
ussp-push "${HW_ADDRESS}@" "${LOCAL_FNAME}" "${REMOTE_FNAME}" >> "${WORKDIR}/ussp-push.log" 2>&1 && (stat -c '%Y %n' "${LOCAL_FNAME}" >> "${WORKDIR}/database/${HW_ADDRESS}.txt"; sleep 3s)
done
fi
done;
Der zugehörige Eintrag in der crontab lautet dann beispielsweise:
# Crontab für nobody # LANG=de_DE.UTF-8 LC_ALL=de_DE.UTF-8 MAILTO=root SHELL=/bin/bash # 0 10-23 * * * /home/gabriel/bin/bt_infobox.sh
Damit wird dieses Skript dann täglich von 10:00-23:00 Uhr alle Stunde ausgeführt. Wenn man eine Infobox realisieren will, an der sich die Leute nicht lange aufhalten, wie auf einer Messe, dann sollte man dieses Skript natürlich öfter ausführen lassen.
Wie funktioniert dieses Skript?
Beim Ausführen wird mit dem Kommando hcitool scan
nach Bluetooth-fähigen Geräten gefahndet. Dann wird für jedes gefundene
Gerät eine Schleife durchlaufen. In diesem Schleife prüft das Skript
zunächst, ob für dieses Gerät bereits einmal eine Datei verschickt
worden ist. Dazu prüft es, ob im Unterverzeichnis database
eine Datei mit dem Namen der Bluetooth-Netzwerkadresse existiert. Ist
dies der Fall, dann wird eine weitere Schleife gestartet, welche alle
Dateien im Unterverzeichnis outbox durchläuft und prüft, ob
eine Datei unter dem jeweiligen Namen und mit dem jeweiligen
Unix-Zeitstempel schon einmal verschickt worden ist. Ist dies nicht der
Fall, dann wird versucht, diese Datei zu verschicken und bei Erfolg ein
Eintrag in der Datenbank gemacht. Die Berücksichtigung des
Unix-Zeitstempels ermöglicht es, eine Datei ohne Änderung ihres
Dateinamens immer wieder in der outbox zu aktualisieren.
Sie wird vom Skript dann als neu erkannt. So etwas macht Sinn für zu
verschickende Dateien, die immer wieder unter dem gleichen Namen einen
neuen Inhalt bekommen, eventuell durch ein anderes Skript.
Ist ein neues Bluetooth-fähiges Gerät erkannt worden, an das noch
nie Dateien verschickt worden ist, dann wird ebenfalls eine Schleife
durchlaufen, welche alle Dateien im Unterverzeichnis outbox abarbeitet, diese an das entsprechende Gerät verschickt und dann in die Datenbank schreibt.
Die Schleife mit dem Befehl sleep 3s versucht
sicherzustellen, dass beim Versand vieler kleiner Dateien keine Datei
beim Versand “verschluckt” wird. Das Skript durchsucht nur eine Ebene im
Unterverzeichnis outbox. Es dürfen daher dort keine Unterverzeichnisse angelegt werden.
Hier ist ein Beispiel für Einträge in der Datenbank, also für Dateien im Unterverzeichnis database:
-rw-r--r-- 1 nobody users 25 26. Sep 21:13 /home/public/Bluetooth-Infobox/database/00:16:B8:13:1D:64.txt -rw-r--r-- 1 nobody users 25 25. Sep 18:00 /home/public/Bluetooth-Infobox/database/00:1E:45:0F:96:32.txt
In einer solchen Datei befinden sich dann Einträge wie:
1166212980 ./Gabriel.jpg
Das zeigt, dass eine Datei namens Gabriel.jpg verschickt
worden ist. Die Zahl am Anfang ist der Unix-Zeitstempel. Da es sich bei
der Datenbank um Textdateien handelt, wird auf dem Server nicht viel
Speicherplatz verbraucht.
Größe eines Mailordners
Dieses einfache und nicht optimierte Skript bestimmt die Postfachgröße eines Benutzers im Ordner /home/public/Mail/ auf dem Caipirinha-Server. Es wird im Rahmen einer snmp-Abfrage zur Postfachgröße benutzt und so aufgerufen:
mailsize.sh Benutzer
mailsize.sh:
#!/bin/bash # Dieses Skript bestimmt die Größe eines Benutzer-Mailordners. # Der Benutzername muss als Argument übergeben werden. # Gabriel Rüeck, 07.01.2010 readonly MAILFOLDER='/home/public/Mail/' # Prüfe auf das Vorhandensein eines gültigen Arguments. # Wurde kein Argument geliefert, beende mit Fehlercode=1. # Wurde kein gültiges Argument geliefert, beende mit Fehlercode=2. if [ $# -lt 1 ]; then exit 1 elif [ ! -d $MAILFOLDER$1 ]; then exit 2 else du -b --max-depth=0 $MAILFOLDER$1 | cut -f1 exit 0 fi
Bandbreite zu entfernten Maschinen
Dieses einfache und nicht optimierte Skript ermittelt die Bandbreite einer TCP-Verbindung von caipirinha.homelinux.org zu den Maschinen caipiroska.homelinux.org und rueeck.name. Es wird ebenfalls im Rahmen einer snmp-Abfrage benutzt und so aufgerufen (hier mit rueeck.name als Beispiel-Argument):
bandwidth.sh rueeck.name
bandwidth.sh:
#!/bin/bash
# Dieses Skript ermittelt die Bandbreite einer TCP-Verbindung zum Zielrechner.
# Gabriel Rüeck, 07.07.2012
# Prüfe auf das Vorhandensein eines gültigen Arguments.
# Wurde kein Argument geliefert, beende mit Fehlercode=1.
if [ $# -lt 1 ]; then
exit 1
fi
# Messe die Bandbreite und berechne den Wert in B/s
bps=$(iperf -f k -x CMSV -c ${1} | sed -n 's/.*Bytes *\([0-9.]\{1,5\} [KM]\)bits.*/\1/p')
value=$(echo ${bps} | cut -f1 -d" ")
decimal=$(echo ${bps} | cut -f2 -d" ")
if [ "${decimal}" = "K" ]; then
echo $(echo "${value:=0}*125" | bc)
elif [ "${decimal}" = "M" ]; then
echo $(echo "${value:=0}*125000" | bc)
fi
Auf den entfernten Maschinen muss dann ein iperf-Dienst laufen. Momentan benutze ich dieses Skript aber nicht, weil der iperf-Dienst auf meinen Maschinen häufig zu Problemen geführt hat.
Ping-Zeiten zu entfernten Maschinen
Dieses einfache und nicht optimierte Skript ermittelt die Ping-Zeiten von caipirinha.homelinux.org zu 3 im Skript selbst definierten Maschinen, in diesem Fall caipiroska.homelinux.org, rueeck.name und zu ein kommerzieller VPN-Anbieter. Es kann die Ping-Zeiten auf den offenen und über das VPN selbst ermitteln. Die gewonnenen Daten werden für mrtg-Grafiken benutzt. Das Skript wird so aufgerufen:
pingtimes.sh gw0|gw1|gw2|tun0|tun1|tun2
pingtimes.sh:
#!/bin/bash
# Dieses speziell auf meine Anwendungszwecke abgestimmte Skript ermittelt die Pingzeiten zu meinen VPN-Gateways.
# Gabriel Rüeck, 08.12.2012
# Prüfe auf das Vorhandensein eines gültigen Arguments. Wurde kein Argument geliefert, beende mit Fehlercode=1.
if [ $# -lt 1 ]; then
exit 1
fi
readonly EVPNLOG='/var/log/openvpn.log'
case "$1" in
gw0) DEST='rueeck.name';;
tun0) DEST=$(ifconfig tun0 2>/dev/null | sed -n 's/.*inet addr:\([0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.\)[0-9]\{1,3\}.*/\1/p')"1"
if [ "${DEST}" == "1" ]; then
exit 2
fi;;
gw1) DEST='caipiroska.homelinux.org';;
tun1) DEST=$(ifconfig tun1 2>/dev/null | sed -n 's/.*inet addr:\([0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.\)[0-9]\{1,3\}.*/\1/p')"1"
if [ "${DEST}" == "1" ]; then
exit 2
fi;;
gw2) DEST=$(cat ${EVPNLOG} | sed -n 's/.*Peer Connection Initiated with \([0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\).*/\1/p' | tail -n1);;
tun2) DEST=$(ifconfig tun2 2>/dev/null | sed -n 's/.*inet addr:\([0-9]\{1,3\}\.[0-9]\{1,3\}\.\)[0-9]\{1,3\}\.[0-9]\{1,3\}.*/\1/p')"0.1"
if [ "${DEST}" == "0.1" ]; then
exit 2
fi;;
*) exit 1;;
esac
# Bestimme die durchschnittliche Ping-Dauer in ms aus 2 Versuchen
PINGTIME=$(ping -c2 -W3 ${DEST} | fgrep "avg" | cut -d"/" -f5 | cut -d"." -f1)
if [ -z "${PINGTIME}" ]; then
echo "0"
else
echo ${PINGTIME}
fi
In diesem Skript ist /var/log/openvpn.log die Log-Datei eines kommerziellen Anbieters. Diese Log-Datei muss natürlich auch in der Konfiguration von openvpn entsprechend konfiguriert werden. In der Log-Datei findet sich nach einem erfolgreichen Aufbau der VPN-Verbindung die IP-Adresse des VPN-Servers, und zwar in einer Zeile mit den Begriffen Peer Connection Initiated with. Das ist eine sinnvolle Sache, weil viele kommerzielle VPN-Anbieter mehrere Server zur Auswahl haben oder gar ein Load-Balancing machen, in dessen Rahmen ein FQDN auf verschiedene IPs aufgelöst werden kann. Der Automatismus in diesem Skript macht daher Sinn.
Wenn eine Verbindung blockiert wird, dann gibt es einen Timeout oder eine Fehlermeldung beim Ping-Kommando, und die nachfolgende Verarbeitung mit dem sed-Kommando resultiert dann in einem leeren String. In diesem Fall gibt das Skript eine 0 zurück. Somit sehe ich in der mrtg-Grafik direkt, dass es bei der entsprechenden Verbindung zu Problemen gekommen ist, weil sich dann eine (blaue) Nulllinie einstellt.
VPN-Datenvolumen ermitteln
Dieses einfache und nicht optimierte Skript ermittelt das aufgelaufene VPN-Datenvolumen von caipirinha.homelinux.org zu 3 entfernten Maschinen, zu denen eine openvpn-Verbindung besteht, in diesem Fall die Maschinen caipiroska.homelinux.org, rueeck.name und zu ein kommerzieller VPN-Anbieter. Das Skript wird ebenfalls im Rahmen einer snmp-Abfrage zur Darstellung einer mrtg-Grafik benutzt. Es wird so aufgerufen:
vpn_traffic.sh tun0|tun1|tun2
vpn_traffic.sh:
#!/bin/bash
# Dieses speziell auf meine Anwendungszwecke abgestimmte Skript ermittelt Verkehrsdaten zu meinen VPN-Gateways.
# Gabriel Rüeck, 05.12.2012
# Prüfe auf das Vorhandensein gültiger Argumente. Wurden keine ausreichenden Argumente geliefert, beende mit Fehlercode=1.
if [ $# -lt 2 ]; then
exit 1
fi
readonly STATUSDIR='/var/run/openvpn/'
case "$1" in
tun0) STATUSFILE='status-rueeck';;
tun1) STATUSFILE='status-caipiroska';;
tun2) STATUSFILE='status-Kommerzielles_VPN';;
*) exit 2;;
esac
case "$2" in
r|read) SEARCHTERM='TCP/UDP read bytes';;
w|write) SEARCHTERM='TCP/UDP write bytes';;
*) exit 2;;
esac
# Lese den aufgelaufenen Datenverkehr aus der gewählten Variable aus
cat ${STATUSDIR}${STATUSFILE} | fgrep "${SEARCHTERM}" | cut -d"," -f2
Kommerzielles_VPN muss freilich durch den Hostnamen oder die IP-Adresse des VPN-Gateways eines kommerziellen Anbieters ersetzt werden. Das Skript benutzt die minütlich aktualisierten Stati der openvpn-Verbindungen und nimmt weiterhin an, dass diese Verbindungen auch ihre Stati im Verzeichnis /var/run/openvpn/ ablegen. Die openvpn-Verbindungen müssen demnach auch entsprechend konfiguriert worden sein.
SNMP
Konzept
SNMP ist eigentlich zur Verwaltung ausgedehnter Netzwerke mit vielen Knoten gedacht. Über das SNMP-Protokoll kann man Daten über den Zustand eines Netzknotens abrufen, also beispielsweise über die Auslastung, den Datendurchsatz, etc. Mit einer geeigneten Software, beispielsweise HP OpenView, kann man sich ein ausgedehntes Netzwerk auch komplett visualisieren und dann gezielt auf einzelne Netzknoten “klicken”, um detaillierte Daten abzurufen. Aber auch im SOHO-Netzwerk kann man mit SNMP einige nützliche Dinge anstellen. Außerdem wird SNMP auch für mrtg benötigt.
Manche SNMP-fähigen Geräte können auch noch beim Auftreten bestimmter Bedingungen eine Nachricht an eine zentrale Station schicken. Man nennt dies einen Trap. Beispielsweise können Router eine Nachricht schicken, wenn eine Verbindung ausfällt.
Auf meinen Maschinen ist SNMP daher natürlich auch eingerichtet. Dabei werden Dienste auf Funktionsfähigkeit geprüft, Log-Dateien und die Maschinenauslastung überwacht, Verkehrsdaten erfasst und auch noch der angeschlossene WLAN-Router überwacht, der ebenfalls SNMP-fähig ist.
Weiterführende Informationen zum Thema SNMP gibt es bei Net-SNMP [1], bei Cisco [2] und natürlich bei Wikipedia [3]. Eine Übersicht von Standard-MIBs und OIDs findet sich bei ByteSphere [4] sowie auf [5] und [6].
Einrichtung des SNMP-Dienstes
Um SNMP einzurichten, muss das Paket net-snmp installiert werden. Dann führt man entweder das interaktive Skript snmpconf -g basic_setup aus, um eine erste Version der SNMP-Konfiguration zu erstellen oder man passt gleich die Datei /etc/snmp/snmpd.conf an, so wie sie hier abgedruckt ist. Eine Beispielkonfiguration mit verschiedenen Einstellungen findet sich auf [7].
########################################################################### # SNMP-Konfiguration # # 05-Dec-2012 Gabriel Rüeck # rouser public rocommunity public localhost rocommunity public 192.168.2.0/24 rocommunity public 192.168.3.0/24 rocommunity public 192.168.4.0/24 ########################################################################### # SECTION: System Information Setup # syslocation "中国110016 沈阳市和平区文体路" syscontact "Gabriel Rüeck <gabriel@caipirinha.homelinux.org>" sysservices 78 ########################################################################### # SECTION: Monitor Various Aspects of the Running Host # # The results are reported in the dskTable section. disk / 30% disk /home 10% disk /home/public/Video 5% disk /var 20% disk /backup 10% # The results are reported in the fileTable section file /var/log/messages 100000 file /var/log/warn 100000 # The results are reported in the laTable section. load 15 10 10 # The results are reported in the prTable section. proc amavisd 3 1 proc apcupsd 1 1 proc atd 1 1 proc authdaemond 10 1 proc clamd 1 1 proc couriertcpd 2 2 proc cron 4 1 proc cupsd 1 1 proc dhcpd 1 1 proc fail2ban-server 1 1 proc famd 1 1 proc freshclam 1 1 proc httpd2-prefork 50 1 proc icecast 10 1 proc master 1 1 proc mdadm 1 1 proc minidlna 5 1 proc mrtg 1 1 proc mysqld 2 1 proc named 1 1 proc nmbd 1 1 proc ntpd 1 1 proc openvpn 6 5 proc pure-ftpd 1 1 proc rsyncd 5 1 proc rsyslogd 1 1 proc saslauthd 1 1 proc sensord 1 1 proc smartd 1 1 proc smbd 20 1 proc sshd 20 1 proc tlsmgr 1 1 ########################################################################### # SECTION: Custom Programs # exec mbox_gabriel /root/bin/mailsize.sh gabriel exec mbox_joselia /root/bin/mailsize.sh joselia exec bw_rueeck /root/bin/bandwidth.sh rueeck.name exec bw_caipiroska /root/bin/bandwidth.sh caipiroska.homelinux.org exec ping_gw0 /root/bin/pingtimes.sh gw0 exec ping_tun0 /root/bin/pingtimes.sh tun0 exec ping_gw1 /root/bin/pingtimes.sh gw1 exec ping_tun1 /root/bin/pingtimes.sh tun1 exec ping_gw2 /root/bin/pingtimes.sh gw2 exec ping_tun2 /root/bin/pingtimes.sh tun2 exec vpn_tun0_r /root/bin/vpn_traffic.sh tun0 read exec vpn_tun0_w /root/bin/vpn_traffic.sh tun0 write exec vpn_tun1_r /root/bin/vpn_traffic.sh tun1 read exec vpn_tun1_w /root/bin/vpn_traffic.sh tun1 write exec vpn_tun2_r /root/bin/vpn_traffic.sh tun2 read exec vpn_tun2_w /root/bin/vpn_traffic.sh tun2 write ########################################################################### # SECTION: Trap Destinations # authtrapenable 2 iquerySecName public createUser public MD5 auth_pwd_local DES crypto_pwd_local #trap2sink localhost public informsink localhost public #trapsess -Ci -v3 -u public -a MD5 -A auth_pwd_trap -x DES -X crypto_pwd_trap -l authPriv localhost monitor -o prNames -o prErrMessage "process table" prErrorFlag != 0 monitor -o dskPath -o dskErrorMsg "dskTable" dskErrorFlag != 0 monitor -o laNames -o laErrMessage "laTable" laErrorFlag != 0 monitor -o fileName -o fileErrorMsg "fileTable" fileErrorFlag != 0
Den Community-Namen public sollte man aus Sicherheitsgründen durch einen selbst gewählten Namen ersetzen. Dieser muss dann aber bei allen SNMP-Knoten im Netzwerk gleich gewählt werden. Gleichermaßen müssen auth_pwd_local und crypto_pwd_local durch möglichst komplexe Passworte ersetzt werden. Diese Passworte dienen zur Authentifizierung (auth_pwd_local) und zur Verschlüsselung (crypto_pwd_local) beim Zugriff auf SNMP-Daten, wenn SNMP in der Version 3 (SNMPv3) zum Einsatz kommt.
Die hier gezeigte Konfigurationsdatei /etc/snmp/snmpd.conf
gliedert sich in fünf Teile und beinhaltet Konfigurationsanweisungen
sowohl für SNMPv2 als auch für SNMPv3. Im ersten Teil werden die
Zugriffsberechtigungen festgelegt; aus Sicherheitsgründen sind diese auf
reine Lesezugriffe vom Server selbst und aus dem SOHO-Netzwerk
beschränkt. Dort sind 3 Netzwerke angegeben, weil der Caipirinha-Server
über mehrere VPNs mit verschiedenen Netzwerken verbunden ist oder selbst
über VPN-Dienste anbietet. Weiterhin wird für SNMPv3 ein Benutzername
(hier: public) angelegt. SNMPv3 kennt verschiedene Sicherheitsmechanismen, welche man sich mit man 5 snmpd.conf
vergegenwärtigen kann. Als Standard wird beim Zugriff auf SNMP-Daten
über SNMPv3 zumindest Authentifizierung verlangt. Verschlüsselung ist
optional.
Im zweiten Abschnitt sind die Kontaktdaten für den Administrator des Caipirinha-Servers und der Maschinenstandort angegeben. Diese Daten erleichtern bei einem umfangreichen Netzwerk die Lokalisierung von Ansprechpartnern, wenn Probleme auf der Maschine auftreten. Der Wert bei sysservices spiegelt die Fähigkeiten des Netzknotens wieder. Details zur Berechnung dieses Wertes finden sich auf [8].
Der dritten Abschnitt selbst gliedert sich in drei Unterabschnitte, in denen verschiedene Kenngrößen überwacht werden. Sobald eine Kenngröße in eine kritische Richtung durchschritten wird, wird eine Mitteilung an den snmptrapd geschickt.
- Bei den angegebenen Partitionen ist der kritische Augenblick das Unterschreiten des angegeben Mindest-Prozentsatzes an freiem Speicher.
- Bei den angegebenen Log-Dateien ist der kritische Augenblick das Überschreiten der Größe. Der angegebene Zahlenwert bezieht sich auf kB als Einheit.
- Bei der Maschinenlast ist der kritische Augenblick das Überschreiten der angegebenen Grenzen. Die drei Werte entsprechen den Zeitintervallen der letzten Minute, der letzten 5 Minuten und der letzten 15 Minuten.
- Bei den Prozessen ist die erste angegebene Zahl der zulässige Maximalwert und die zweite angegebene Zahl der zulässige Minimalwert. Ein Überschreiten des Maximalwertes oder ein Unterschreiten des Minimalwertes setzt ein Fehler-Flag und in der abgedruckten Konfiguration auch dazu, dass ein Trap geschickt wird. Der snmptrap-Dienst wird daraus eine E-Mail erzeugen und an den Systemadministrator schicken. Es macht natürlich nur Sinn, hier solche Prozesse beobachten zu lassen, die eigentlich ununterbrochen laufen sollen.
Im vierten Abschnitt sind Skripte angegeben, die aus dem SNMP-Dienst heraus mit festzulegenden Argumenten aufgerufen werden können. Jeder Aufruf selbst bekommt auch noch einen Namen (beispielsweise mbox_gabriel oder mbox_joselia). Die hier erwähnten Shell-Skripte mailsize.sh, bandwidth.sh, pingtimes.sh und vpn_traffic.sh sind in Admin-Skripte dokumentiert.
Im fünften Abschnitt sind schließlich die Daten für den snmptrapd angegeben. Man erkennt mehrere Schlüsselworte. Mit authtrapenable werden versuchte SNMP-Abfragen mit einem fehlerhaften Login entweder an den snmptrapd geschickt (authtrapenable 1) oder eben nicht (authtrapenable 2). Mit iquerySecName wird der SNMPv3-Benutzername festgelegt, unter dem die Abfragen beim snmpd durchgeführt werden. Dieser Name muss gleich dem unter dem Schlüsselwort rouser angegebenen Benutzernamen sein. Mit createUser werden die Algorithmen und die Passworte zur Authentifizierung (auth_pwd_local) und zur Verschlüsselung (crypto_pwd_local) beim Zugriff mit dem entsprechenden SNMPv3-Benutzernamen auf lokale SNMP-Daten festgelegt. Man kann das Verschlüsselungspasswort (crypto_pwd_local) auch weglassen und die Authentifizierung und Verschlüsselung mit dem gleichen Passwort (in diesem Fall dann auth_pwd_local) durchführen. In diesem Fall muss die createUser-Anweisung so lauten:
createUser public MD5 auth_pwd_local DES crypto_pwd_local
Das Schlüsselwort trap2sink gibt das Ziel und den SNMPv2-Community-Namen an, an den die Traps geschickt werden. Achtung, hier wird SNMPv2 benutzt, während die Abfrage der SNMP-Werte beim snmpd mit SNMPv3 läuft! trap2sink ist hier allerdings auskommentiert, zu Gunsten von informsink. Durch informsink wird kein Trap, sondern eine Inform-Mitteilung an den snmptrapd geschickt. Das hat den Vorteil, dass der snmptrapd den Erhalt der Mitteilung bestätigt. Laufen sowohl snmpd als auch snmptrapd auf der gleichen Maschine, ist das unwichtig. Ist aber der snmptrapd auf einer entfernten Maschine, ist informsink eindeutig die bessere Wahl, denn so vermeidet man, dass die UDP-Pakete eines Trap verloren gehen können. Man kann bei beiden Schlüsselworten sowohl eine lokale als auch eine entfernte Maschine angeben. Beim Caipirinha-Server und Caipiroska-Server laufen die snmptrapd auf den gleichen Maschinen. Damit kann auch ein Trap gesendet werden, wenn die Netzwerkverbindung gerade down ist. In einem lokalen Netz, bei dem man sich sicher ist, dass die Verbindungen immer up sind, kann man den snmptrapd auch auf einer Maschine zentralisieren und von dort aus das gesamte Netzwerk überwachen.
Die vier monitor-Anweisungen legen fest, dass beim
Auftreten einer Fehlerbedingung ein Trap zu schicken ist. Die
entsprechende Syntax habe ich direkt aus man 5 snmpd.conf heraus kopiert. Man hätte auch die Anweisung defaultMonitors yes benutzen können, aber diese beinhaltet noch weitere Prüfungen, die ich hier nicht haben wollte.
Mit dem Schlüsselwort trapsess kann man Traps und Informs auch über SNMPv3 zu einem snmptrapd auf einer lokalen oder entfernten Maschine schicken. Im falle einer entfernten Maschine muss man localhost durch den Maschinennamen oder die IP-Adresse ersetzen. Die Parameter public, auth_pwd_trap und crypto_pwd_trap müssen denen des snmptrapd entsprechen. Mit dieser Konfiguration wird die Nachricht vom snmpd zum snmptrapd dann sowohl an einen gültigen Login gebunden als auch verschlüsselt. Die Option -Ci legt fest, dass eine Inform-Mitteilung geschickt wird. Fehlt diese Option, wird lediglich eine (unbestätigte) Trap-Mitteilung geschickt.
Zum Vergleich ist hier eine Konfigurationsdatei angegeben, bei der Inform-Mittelungen an eine entfernte Maschine geschickt werden:
########################################################################### # SNMP-Konfiguration # # 05-Dec-2012 Gabriel Rüeck # rouser public rocommunity public localhost rocommunity public 124.95.128.109/32 ########################################################################### # SECTION: System Information Setup # syslocation "辽宁省沈阳市" syscontact "Gabriel Rüeck <gabriel@rueeck.de>" sysservices 78 ########################################################################### # SECTION: Monitor Various Aspects of the Running Host # # The results are reported in the dskTable section. disk / 50% disk /home 10% disk /tmp 20% disk /var 20% # The results are reported in the fileTable section file /var/log/messages 50000 file /var/log/warn 50000 # The results are reported in the laTable section. load 5 3 1 # The results are reported in the prTable section. proc atd 1 1 proc clamd 1 1 proc cron 4 1 proc fail2ban-server 1 1 proc famd 1 1 proc freshclam 1 1 proc httpd2-prefork 600 1 proc master 1 1 proc mdadm 1 1 proc mrtg 1 1 proc mysqld 2 1 proc named 1 1 proc ntpd 1 1 proc openvpn 2 1 proc rsyncd 5 1 proc rsyslogd 1 1 proc sensord 1 1 proc smartd 1 1 proc sshd 20 1 ########################################################################### # SECTION: Custom Programs # exec bw_rueeck /root/bin/bandwidth.sh rueeck.name exec bw_caipiroska /root/bin/bandwidth.sh caipiroska.homelinux.org ########################################################################### # SECTION: Trap Destinations # authtrapenable 1 iquerySecName public createUser public MD5 auth_pwd_local DES crypto_pwd_local #informsink caipirinha.homelinux.org public trapsess -Ci -v3 -u public -a MD5 -A auth_pwd_trap -x DES -X crypto_pwd_trap -l authPriv caipirinha.homelinux.org monitor -o prNames -o prErrMessage "process table" prErrorFlag != 0 monitor -o dskPath -o dskErrorMsg "dskTable" dskErrorFlag != 0 monitor -o laNames -o laErrMessage "laTable" laErrorFlag != 0 monitor -o fileName -o fileErrorMsg "fileTable" fileErrorFlag != 0
Nach der Anpassung der Konfigurationsdatei /etc/snmp/snmpd.conf muss man noch den snmpd noch starten. Eigentlich geschieht dies ja mit /etc/init.d/snmpd start. Allerdings liest der snmpd beim Start gleich alle möglichen Konfigurationsdateien aus unterschiedlichen Verzeichnissen ein (siehe man 5 snmp_config). Das ist eine böse Falle, die mich viel Zeit gekostet hat. So werden unter anderem existierende SNMPv3-Benutzerdaten aus /var/lib/net-snmp/snmpd.conf
eingelesen, die dann die Einstellungen aus der aktuellen
Konfigurationsdatei zunichte machen. Deshalb sollte man nach dem
Anpassen der Konfigurationsdatei den snmpd mit snmpd -C -c /etc/snmp/snmpd.conf unter alleiniger Berücksichtigung dieser Konfigurationsdatei neu starten. In diesem Fall werden dann die SNMPv3-Benutzer in /var/lib/net-snmp/snmpd.conf von der Konfigurationsdatei /etc/snmp/snmpd.conf übernommen.
Einrichtung des SNMPTRAP-Dienstes
Wie bereits erwähnt, läuft auf meinen Maschinen nicht nur der snmpd, sondern auch noch der snmptrapd. Der Caipirinha-Server [9] ist damit zugleich Quelle von SNMP-Mitteilungen, die den Server selbst betreffen als auch zentrale Station zur Aufnahme aller Meldungen von Geräten aus dem entsprechenden lokalen Netz. Es handelt sich also bei snmptrapd um einen eigenständigen Dienst, der auf Port 162/udp auf eingehende Mitteilungen von SNMP-Agenten wartet.
Auch für den snmptrapd gibt es eine Konfigurationsdatei, nämlich /etc/snmp/snmptrapd.conf. Diese ist hier abgedruckt:
########################################################################### # SNMPTRAP-Konfiguration # # 30-Nov-2012 Gabriel Rüeck # # donotfork: Do not fork from the shell # arguments: (1|yes|true|0|no|false) doNotFork no # pidfile: Store Process ID in file # arguments: PID file pidFile /var/run/snmptrapd.pid # ignoreauthfailure: Ignore authentication failure traps # arguments: (1|yes|true|0|no|false) ignoreAuthFailure yes authCommunity log,execute public authUser log,execute public authUser log,execute public_2 createUser public MD5 auth_pwd_trap DES crypto_pwd_trap createUser public_2 MD5 auth_pwd_trap_2 DES crypto_pwd_trap_2 traphandle default /usr/bin/traptoemail -f "System Administrator <root@caipirinha.homelinux.org>" root@caipirinha.homelinux.org format1 %04.4y-%02.2m-%02.2l %02.2h:%02.2j From %B: %W \n format2 %04.4y-%02.2m-%02.2l %02.2h:%02.2j From %B: %W \n
Auch hier muss der Community-Name public durch den im gesamten Netzwerk einheitlich benutzten Community-Namen ersetzt werden. Mit authUser und createUser wird ein SNMPv3-Benutzer angelegt. auth_pwd_trap ist das Passwort zur Authentifizierung beim snmptrapd, und crypto_pwd_trap ist das Passwort zum Verschlüsseln der Daten. MD5 ist der bei der Authentifizierung zum Einsatz kommende Algorithmus, und DES kommt bei der Verschlüsselung zum Einsatz. auth_pwd_trap und crypto_pwd_trap müssen gleich sein wie bei der Konfiguration des snmpd auf einer Maschine, die diesem snmptrapd einen Trap oder eine Inform-Mitteilung schicken will. Auch hier kann man das Verschlüsselungspasswort (crypto_pwd_trap) weglassen und die Authentifizierung und Verschlüsselung mit dem gleichen Passwort (in diesem Fall dann auth_pwd_trap) durchführen. In diesem Fall muss die createUser-Anweisung so lauten:
createUser public MD5 auth_pwd_trap DES
Es ist auch möglich, mehrere SNMPv3-Benutzer anzulegen. Im Beispiel hier wurde mit public_2, auth_pwd_trap_2 und crypto_pwd_trap_2 ein zweiter SNMPv3-Benutzer angelegt, der diesem snmptrapd Mitteilungen schicken kann. Dies macht dann Sinn, wenn der snmptrapd Traps von unterschiedlichen Maschinen in Empfang nehmen soll, bei denen aber die jeweiligen Administratoren nichts von den Logins der anderen Maschinen wissen sollen. Man könnte natürlich auch generell für den snmptrapd einen ganz anderen SNMPv3-Benutzer nehmen, der nichts mit irgendeinem SNMPv3-Benutzer auf einer der Maschinen zu tun hat. Dies wäre ohne Zweifel die sicherste Lösung.
Die Anweisung traphandle legt fest, was beim Auftreten eines Traps zu tun ist. In diesem Fall wird eine E-Mail an root geschickt. format1 und format2 legen das Format für SNMPv1-Traps und SNMPv2/SNMPv3-Traps fest. Ich habe hier noch ein Format für SNMPv1 festgelegt, obwohl SNMPv1 nun inzwischen wirklich aus der Mode kommt, weil einige einfachen Router tatsächlich auch heute nur SNMPv1 beherrschen.
Es gibt für die Konfigurationsdatei auch eine Anweisung logOption,
mit dem man in der Konfigurationsdatei einstellen können sollte, wohin
die Meldungen geloggt werden sollen. Allerdings funktioniert diese bei
OpenSuSE 11.4 nicht, und wenn man snmptrapd -H aufruft,
kommt ja auch eine entsprechende Meldung, die besagt, lass kein
Log-Handling aktiv ist. Alle Mitteilungen werden daher leider nach /var/log/messages geschrieben, ob man das will oder nicht. Beim Caipiroska-Server [10] sieht das dann beispielsweise so aus:
Nov 26 07:40:49 caipiroska snmptrapd[18445]: localhost [UDP: [127.0.0.1]:56402->[127.0.0.1]:162]: Trap , DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (22) 0:00:00.22, SNMPv2-MIB::snmpTrapOID.0 = OID: DISMAN-EVENT-MIB::mteTriggerFired, DISMAN-EVENT-MIB::mteHotTrigger.0 = STRING: process table, DISMAN-EVENT-MIB::mteHotTargetName.0 = STRING: , DISMAN-EVENT-MIB::mteHotContextName.0 = STRING: , DISMAN-EVENT-MIB::mteHotOID.0 = OID: UCD-SNMP-MIB::prErrorFlag.24, DISMAN-EVENT-MIB::mteHotValue.0 = INTEGER: 1, UCD-SNMP-MIB::prNames.24 = STRING: smbd, UCD-SNMP-MIB::prErrMessage.24 = STRING: No smbd process running Nov 26 07:40:49 caipiroska snmptrapd[18445]: localhost [UDP: [127.0.0.1]:56402->[127.0.0.1]:162]: Trap , DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (23) 0:00:00.23, SNMPv2-MIB::snmpTrapOID.0 = OID: DISMAN-EVENT-MIB::mteTriggerFired, DISMAN-EVENT-MIB::mteHotTrigger.0 = STRING: dskTable, DISMAN-EVENT-MIB::mteHotTargetName.0 = STRING: , DISMAN-EVENT-MIB::mteHotContextName.0 = STRING: , DISMAN-EVENT-MIB::mteHotOID.0 = OID: UCD-SNMP-MIB::dskErrorFlag.3, DISMAN-EVENT-MIB::mteHotValue.0 = INTEGER: 1, UCD-SNMP-MIB::dskPath.3 = STRING: /home/public/Video, UCD-SNMP-MIB::dskErrorMsg.3 = STRING: /home/public/Video: less than 5% free (= 100%)
Die erste Meldung sagt aus, dass kein smbd-Prozess läuft. Die zweite Meldung sagt aus, dass auf der Partition /home/public/Video weniger als 5% freier Festplattenspeicher ist. Der snmptrapd schickt auch entsprechende E-Mails, und die zu den zwei Meldungen gehörenden E-Mails haben genau den gleichen Inhalt, wie man hier erkennen kann:
Host: localhost (UDP: [127.0.0.1]:56402->[127.0.0.1]:162)
DISMAN-EVENT-MIB::sysUpTimeInstance 0:0:00:00.22
SNMPv2-MIB::snmpTrapOID.0 DISMAN-EVENT-MIB::mteTriggerFired
DISMAN-EVENT-MIB::mteHotTrigger.0 process table
DISMAN-EVENT-MIB::mteHotTargetName.0
DISMAN-EVENT-MIB::mteHotContextName.0
DISMAN-EVENT-MIB::mteHotOID.0 UCD-SNMP-MIB::prErrorFlag.24
DISMAN-EVENT-MIB::mteHotValue.0 1
UCD-SNMP-MIB::prNames.24 smbd
UCD-SNMP-MIB::prErrMessage.24 No smbd process running
Host: localhost (UDP: [127.0.0.1]:56402->[127.0.0.1]:162)
DISMAN-EVENT-MIB::sysUpTimeInstance 0:0:00:00.23
SNMPv2-MIB::snmpTrapOID.0 DISMAN-EVENT-MIB::mteTriggerFired
DISMAN-EVENT-MIB::mteHotTrigger.0 dskTable
DISMAN-EVENT-MIB::mteHotTargetName.0
DISMAN-EVENT-MIB::mteHotContextName.0
DISMAN-EVENT-MIB::mteHotOID.0 UCD-SNMP-MIB::dskErrorFlag.3
DISMAN-EVENT-MIB::mteHotValue.0 1
UCD-SNMP-MIB::dskPath.3 /home/public/Video
UCD-SNMP-MIB::dskErrorMsg.3 /home/public/Video: less than 5% free (= 100%)
Durch den E-Mail-Mechanismus kann man sich als Systemadministrator daher direkt informieren lassen, wenn auf einem der Server etwas aus dem Ruder läuft. Das ist eine sehr praktische Sache, insbesondere, wenn man eine solche E-Mail gleich noch auf dem Smartphone empfangen kann.

Der snmptrapd muss über das Kommando snmptrapd gestartet werden. Es ist leider nicht möglich, einen automatischen Start über den Runlevel-Editor
einzustellen. Dies wird auf dem Caipirinha-Server im Rahmen eines
Skripts durchgeführt, welches der Systemadministrator nach dem Start des
Systems ausführen muss. Wie beim spnmd sollte man den snmptrapd nach
dem Ändern der Konfigurationsdatei mit snmptrapd -C -c /etc/snmp/snmptrapd.conf starten, weil auch der snmptrapd beim Start mehrere Konfigurationsdateien aus unterschiedlichen Verzeichnissen einliest (siehe man 5 snmp_config), unter anderem aus /var/lib/net-snmp/snmptrapd.conf.
Konfiguration von SNMP bei DSL-Routern
Oft ist es möglich, selbst bei SOHO-Routern SNMP zu konfigurieren; das nebenstehende Bild zeigt, wie man dies bei der “EasyBox 602” von Vodafone macht. Trägt man dort die IP-Adresse des Caipiroska-Servers im Heimnetzwerk ein und konfiguriert den Community-Namen korrekt, so kann der DSL-Router Traps an den Caipiroska-Server schicken, beispielsweise, wenn die DSL-Verbindung wegen des in Deutschland einmal am Tag stattfindenden IP-Adresswechsels kurzzeitig zusammenbricht. Dann bekommt man mindestens einen Trap mit der “Line down”-Information und einen mit der “Line up”-Information, üblicherweise kurze Zeit danach. Man erkennt hier auch, dass es Sinn macht, einen snmptrapd im Heimnetz laufen zu lassen und nicht auf eine entfernte Maschine zu verweisen, die ja dann nicht verfügbar ist, wenn die DSL-Verbindung gerade zusammengebrochen ist. Bei der von snmptrapd erzeugten E-Mail wird dagegen vom smtpd über einen längeren Zeitraum hinweg mehrmals eine Zustellung versucht.
Beispiele für SNMP-Abfragen
Einen ersten Überblick über die SNMP-Variablen einer Maschine verschafft man sich mit snmpwalk -v2c -cpublic localhost oder, wenn SNMPv3 zum Einsatz kommen soll, mit snmpwalk -v3 -u public -l authNoPriv -a MD5 -A auth_pwd_local localhost. Die Option authNoPriv
besagt, dass hier zwar eine Authentifizierung durchgeführt wird, aber
keine Verschlüsselung der Daten, die übertragen werden. Leider habe ich
mit der Option authPriv und der Angabe des crypto_pwd_local nur eine Fehlermeldung bekommen.
Die Ausgabe dieser Abfrage kann jedenfalls zu einer recht langen Liste führen.
System-Statistiken kann man sich mit snmpwalk -v2c -cpublic localhost .1.3.6.1.4.1.2021.11 bzw. snmpwalk -v3 -u public -l authNoPriv -a MD5 -A auth_pwd_local localhost .1.3.6.1.4.1.2021.11 anzeigen lassen [11], [12]. Dies liefert beispielsweise:
UCD-SNMP-MIB::ssIndex.0 = INTEGER: 1 UCD-SNMP-MIB::ssErrorName.0 = STRING: systemStats UCD-SNMP-MIB::ssSwapIn.0 = INTEGER: 0 kB UCD-SNMP-MIB::ssSwapOut.0 = INTEGER: 0 kB UCD-SNMP-MIB::ssIOSent.0 = INTEGER: 353 blocks/s UCD-SNMP-MIB::ssIOReceive.0 = INTEGER: 0 blocks/s UCD-SNMP-MIB::ssSysInterrupts.0 = INTEGER: 537 interrupts/s UCD-SNMP-MIB::ssSysContext.0 = INTEGER: 796 switches/s UCD-SNMP-MIB::ssCpuUser.0 = INTEGER: 0 UCD-SNMP-MIB::ssCpuSystem.0 = INTEGER: 1 UCD-SNMP-MIB::ssCpuIdle.0 = INTEGER: 95 UCD-SNMP-MIB::ssCpuRawUser.0 = Counter32: 7043838 UCD-SNMP-MIB::ssCpuRawNice.0 = Counter32: 1157149 UCD-SNMP-MIB::ssCpuRawSystem.0 = Counter32: 5023506 UCD-SNMP-MIB::ssCpuRawIdle.0 = Counter32: 147653397 UCD-SNMP-MIB::ssCpuRawWait.0 = Counter32: 9671287 UCD-SNMP-MIB::ssCpuRawKernel.0 = Counter32: 0 UCD-SNMP-MIB::ssCpuRawInterrupt.0 = Counter32: 352 UCD-SNMP-MIB::ssIORawSent.0 = Counter32: 1866410120 UCD-SNMP-MIB::ssIORawReceived.0 = Counter32: 2797478450 UCD-SNMP-MIB::ssRawInterrupts.0 = Counter32: 597294992 UCD-SNMP-MIB::ssRawContexts.0 = Counter32: 1239253106 UCD-SNMP-MIB::ssCpuRawSoftIRQ.0 = Counter32: 338170 UCD-SNMP-MIB::ssRawSwapIn.0 = Counter32: 0 UCD-SNMP-MIB::ssRawSwapOut.0 = Counter32: 0
Angaben über Partitionen und dere Auslastung bekommt man mit snmpwalk -v2c -cpublic localhost .1.3.6.1.4.1.2021.9 bzw. snmpwalk -v3 -u public -l authNoPriv -a MD5 -A auth_pwd_local localhost .1.3.6.1.4.1.2021.9 [13], [14]. Auf dem Caipirinha-Server ergibt dies dann:
UCD-SNMP-MIB::dskIndex.1 = INTEGER: 1 UCD-SNMP-MIB::dskIndex.2 = INTEGER: 2 UCD-SNMP-MIB::dskIndex.3 = INTEGER: 3 UCD-SNMP-MIB::dskIndex.4 = INTEGER: 4 UCD-SNMP-MIB::dskIndex.5 = INTEGER: 5 UCD-SNMP-MIB::dskPath.1 = STRING: / UCD-SNMP-MIB::dskPath.2 = STRING: /home UCD-SNMP-MIB::dskPath.3 = STRING: /home/public/Video UCD-SNMP-MIB::dskPath.4 = STRING: /var UCD-SNMP-MIB::dskPath.5 = STRING: /backup UCD-SNMP-MIB::dskDevice.1 = STRING: rootfs UCD-SNMP-MIB::dskDevice.2 = STRING: /dev/mapper/cr_md2 UCD-SNMP-MIB::dskDevice.3 = STRING: /dev/md3 UCD-SNMP-MIB::dskDevice.4 = STRING: /dev/mapper/cr_md1 UCD-SNMP-MIB::dskDevice.5 = STRING: /dev/mapper/cr_sde1 ... UCD-SNMP-MIB::dskMinPercent.1 = INTEGER: 30 UCD-SNMP-MIB::dskMinPercent.2 = INTEGER: 10 UCD-SNMP-MIB::dskMinPercent.3 = INTEGER: 5 UCD-SNMP-MIB::dskMinPercent.4 = INTEGER: 20 UCD-SNMP-MIB::dskMinPercent.5 = INTEGER: 10 UCD-SNMP-MIB::dskTotal.1 = INTEGER: 51612944 UCD-SNMP-MIB::dskTotal.2 = INTEGER: 901563648 UCD-SNMP-MIB::dskTotal.3 = INTEGER: 2147483647 UCD-SNMP-MIB::dskTotal.4 = INTEGER: 8253744 UCD-SNMP-MIB::dskTotal.5 = INTEGER: 1922857728 UCD-SNMP-MIB::dskAvail.1 = INTEGER: 37133060 UCD-SNMP-MIB::dskAvail.2 = INTEGER: 622951360 UCD-SNMP-MIB::dskAvail.3 = INTEGER: 922618048 UCD-SNMP-MIB::dskAvail.4 = INTEGER: 2117264 UCD-SNMP-MIB::dskAvail.5 = INTEGER: 1687921664 UCD-SNMP-MIB::dskUsed.1 = INTEGER: 11858084 UCD-SNMP-MIB::dskUsed.2 = INTEGER: 232815424 UCD-SNMP-MIB::dskUsed.3 = INTEGER: 2147483647 UCD-SNMP-MIB::dskUsed.4 = INTEGER: 5717212 UCD-SNMP-MIB::dskUsed.5 = INTEGER: 234936064 UCD-SNMP-MIB::dskPercent.1 = INTEGER: 24 UCD-SNMP-MIB::dskPercent.2 = INTEGER: 27 UCD-SNMP-MIB::dskPercent.3 = INTEGER: 76 UCD-SNMP-MIB::dskPercent.4 = INTEGER: 73 UCD-SNMP-MIB::dskPercent.5 = INTEGER: 12 ... UCD-SNMP-MIB::dskErrorFlag.1 = INTEGER: noError(0) UCD-SNMP-MIB::dskErrorFlag.2 = INTEGER: noError(0) UCD-SNMP-MIB::dskErrorFlag.3 = INTEGER: noError(0) UCD-SNMP-MIB::dskErrorFlag.4 = INTEGER: noError(0) UCD-SNMP-MIB::dskErrorFlag.5 = INTEGER: noError(0) UCD-SNMP-MIB::dskErrorMsg.1 = STRING: UCD-SNMP-MIB::dskErrorMsg.2 = STRING: UCD-SNMP-MIB::dskErrorMsg.3 = STRING: UCD-SNMP-MIB::dskErrorMsg.4 = STRING: UCD-SNMP-MIB::dskErrorMsg.5 = STRING:
Einen Überblick über die Interfaces an einer Maschine bekommt man mit snmpwalk -v2c -cpublic localhost .1.3.6.1.2.1.2.2.1 bzw. snmpwalk -v3 -u public -l authNoPriv -a MD5 -A auth_pwd_local localhost .1.3.6.1.2.1.2.2.1 [15]. Dies liefert als Ausgabe auf dem Caipirinha-Server:
IF-MIB::ifIndex.1 = INTEGER: 1 IF-MIB::ifIndex.2 = INTEGER: 2 IF-MIB::ifIndex.3 = INTEGER: 3 IF-MIB::ifIndex.68 = INTEGER: 68 IF-MIB::ifIndex.70 = INTEGER: 70 IF-MIB::ifIndex.72 = INTEGER: 72 IF-MIB::ifIndex.73 = INTEGER: 73 IF-MIB::ifIndex.74 = INTEGER: 74 IF-MIB::ifDescr.1 = STRING: lo IF-MIB::ifDescr.2 = STRING: eth0 IF-MIB::ifDescr.3 = STRING: eth1 IF-MIB::ifDescr.68 = STRING: tun2 IF-MIB::ifDescr.70 = STRING: tun0 IF-MIB::ifDescr.72 = STRING: tun1 IF-MIB::ifDescr.73 = STRING: tun4 IF-MIB::ifDescr.74 = STRING: tun3 ... IF-MIB::ifMtu.1 = INTEGER: 16436 IF-MIB::ifMtu.2 = INTEGER: 1500 IF-MIB::ifMtu.3 = INTEGER: 1500 IF-MIB::ifMtu.68 = INTEGER: 1500 IF-MIB::ifMtu.70 = INTEGER: 1500 IF-MIB::ifMtu.72 = INTEGER: 1500 IF-MIB::ifMtu.73 = INTEGER: 1500 IF-MIB::ifMtu.74 = INTEGER: 1500 IF-MIB::ifSpeed.1 = Gauge32: 10000000 IF-MIB::ifSpeed.2 = Gauge32: 1000000000 IF-MIB::ifSpeed.3 = Gauge32: 10000000 IF-MIB::ifSpeed.68 = Gauge32: 0 IF-MIB::ifSpeed.70 = Gauge32: 0 IF-MIB::ifSpeed.72 = Gauge32: 0 IF-MIB::ifSpeed.73 = Gauge32: 0 IF-MIB::ifSpeed.74 = Gauge32: 0 ... IF-MIB::ifAdminStatus.1 = INTEGER: up(1) IF-MIB::ifAdminStatus.2 = INTEGER: up(1) IF-MIB::ifAdminStatus.3 = INTEGER: down(2) IF-MIB::ifAdminStatus.68 = INTEGER: up(1) IF-MIB::ifAdminStatus.70 = INTEGER: up(1) IF-MIB::ifAdminStatus.72 = INTEGER: up(1) IF-MIB::ifAdminStatus.73 = INTEGER: up(1) IF-MIB::ifAdminStatus.74 = INTEGER: up(1) IF-MIB::ifOperStatus.1 = INTEGER: up(1) IF-MIB::ifOperStatus.2 = INTEGER: up(1) IF-MIB::ifOperStatus.3 = INTEGER: down(2) IF-MIB::ifOperStatus.68 = INTEGER: up(1) IF-MIB::ifOperStatus.70 = INTEGER: up(1) IF-MIB::ifOperStatus.72 = INTEGER: up(1) IF-MIB::ifOperStatus.73 = INTEGER: up(1) IF-MIB::ifOperStatus.74 = INTEGER: up(1) ... IF-MIB::ifInOctets.1 = Counter32: 123922180 IF-MIB::ifInOctets.2 = Counter32: 2916738370 IF-MIB::ifInOctets.3 = Counter32: 0 IF-MIB::ifInOctets.68 = Counter32: 3764554219 IF-MIB::ifInOctets.70 = Counter32: 99214022 IF-MIB::ifInOctets.72 = Counter32: 5293853 IF-MIB::ifInOctets.73 = Counter32: 0 IF-MIB::ifInOctets.74 = Counter32: 0 ...
Interessanter is es aber, diese Abfrage bei einem Router zu machen. Ein solches Beispiel ist hier wiedergegeben:
IF-MIB::ifIndex.1 = INTEGER: 1 IF-MIB::ifIndex.2 = INTEGER: 2 IF-MIB::ifIndex.3 = INTEGER: 3 IF-MIB::ifIndex.4 = INTEGER: 4 IF-MIB::ifIndex.12 = INTEGER: 12 IF-MIB::ifIndex.21 = INTEGER: 21 IF-MIB::ifIndex.22 = INTEGER: 22 IF-MIB::ifIndex.23 = INTEGER: 23 IF-MIB::ifIndex.24 = INTEGER: 24 IF-MIB::ifIndex.25 = INTEGER: 25 IF-MIB::ifIndex.26 = INTEGER: 26 IF-MIB::ifDescr.1 = STRING: LOCAL_LOOPBACK IF-MIB::ifDescr.2 = STRING: LAN IF-MIB::ifDescr.3 = STRING: WLAN IF-MIB::ifDescr.4 = STRING: ATM1 IF-MIB::ifDescr.12 = STRING: PPPoE1 IF-MIB::ifDescr.21 = STRING: WDS1 IF-MIB::ifDescr.22 = STRING: WDS2 IF-MIB::ifDescr.23 = STRING: WDS3 IF-MIB::ifDescr.24 = STRING: WDS4 IF-MIB::ifDescr.25 = STRING: WAN2 IF-MIB::ifDescr.26 = STRING: COM1 ... IF-MIB::ifMtu.1 = INTEGER: 1500 IF-MIB::ifMtu.2 = INTEGER: 1500 IF-MIB::ifMtu.3 = INTEGER: 1500 IF-MIB::ifMtu.4 = INTEGER: 1500 IF-MIB::ifMtu.12 = INTEGER: 1492 IF-MIB::ifMtu.21 = INTEGER: 1500 IF-MIB::ifMtu.22 = INTEGER: 1500 IF-MIB::ifMtu.23 = INTEGER: 1500 IF-MIB::ifMtu.24 = INTEGER: 1500 IF-MIB::ifMtu.25 = INTEGER: 1500 IF-MIB::ifMtu.26 = INTEGER: 1500 IF-MIB::ifSpeed.1 = Gauge32: 0 IF-MIB::ifSpeed.2 = Gauge32: 100000000 IF-MIB::ifSpeed.3 = Gauge32: 54000000 IF-MIB::ifSpeed.4 = Gauge32: 224000 IF-MIB::ifSpeed.12 = Gauge32: 2304000 IF-MIB::ifSpeed.21 = Gauge32: 54000000 IF-MIB::ifSpeed.22 = Gauge32: 54000000 IF-MIB::ifSpeed.23 = Gauge32: 54000000 IF-MIB::ifSpeed.24 = Gauge32: 54000000 IF-MIB::ifSpeed.25 = Gauge32: 100000000 IF-MIB::ifSpeed.26 = Gauge32: 0 ... IF-MIB::ifAdminStatus.1 = INTEGER: up(1) IF-MIB::ifAdminStatus.2 = INTEGER: up(1) IF-MIB::ifAdminStatus.3 = INTEGER: up(1) IF-MIB::ifAdminStatus.4 = INTEGER: up(1) IF-MIB::ifAdminStatus.12 = INTEGER: up(1) IF-MIB::ifAdminStatus.21 = INTEGER: up(1) IF-MIB::ifAdminStatus.22 = INTEGER: up(1) IF-MIB::ifAdminStatus.23 = INTEGER: up(1) IF-MIB::ifAdminStatus.24 = INTEGER: up(1) IF-MIB::ifAdminStatus.25 = INTEGER: 0 IF-MIB::ifAdminStatus.26 = INTEGER: 0 IF-MIB::ifOperStatus.1 = INTEGER: up(1) IF-MIB::ifOperStatus.2 = INTEGER: up(1) IF-MIB::ifOperStatus.3 = INTEGER: up(1) IF-MIB::ifOperStatus.4 = INTEGER: up(1) IF-MIB::ifOperStatus.12 = INTEGER: up(1) IF-MIB::ifOperStatus.21 = INTEGER: up(1) IF-MIB::ifOperStatus.22 = INTEGER: up(1) IF-MIB::ifOperStatus.23 = INTEGER: up(1) IF-MIB::ifOperStatus.24 = INTEGER: up(1) IF-MIB::ifOperStatus.25 = INTEGER: 0 IF-MIB::ifOperStatus.26 = INTEGER: 0 ... IF-MIB::ifInOctets.1 = Counter32: 210 IF-MIB::ifInOctets.2 = Counter32: 0 IF-MIB::ifInOctets.3 = Counter32: 101309606 IF-MIB::ifInOctets.4 = Counter32: 511415216 IF-MIB::ifInOctets.12 = Counter32: 250011578 IF-MIB::ifInOctets.21 = Counter32: 0 IF-MIB::ifInOctets.22 = Counter32: 0 IF-MIB::ifInOctets.23 = Counter32: 0 IF-MIB::ifInOctets.24 = Counter32: 0 IF-MIB::ifInOctets.25 = Counter32: 0 IF-MIB::ifInOctets.26 = Counter32: 0 ... IF-MIB::ifOutOctets.1 = Counter32: 0 IF-MIB::ifOutOctets.2 = Counter32: 62445328 IF-MIB::ifOutOctets.3 = Counter32: 0 IF-MIB::ifOutOctets.4 = Counter32: 109637356 IF-MIB::ifOutOctets.12 = Counter32: 50021044 IF-MIB::ifOutOctets.21 = Counter32: 0 IF-MIB::ifOutOctets.22 = Counter32: 0 IF-MIB::ifOutOctets.23 = Counter32: 0 IF-MIB::ifOutOctets.24 = Counter32: 0 IF-MIB::ifOutOctets.25 = Counter32: 0 IF-MIB::ifOutOctets.26 = Counter32: 0
Die interessanten Interfaces sind hier #12 (PPPoE1), welches Statistiken der über ADSL transportierten Datenmengen an diesem Router zählt und #3, welches die über das WLAN transportierten Datenmengen protokolliert.
Backup
Ich denke, über den Sinn von Backups muss hier nichts erzählt werden. Dennoch empfehle ich zunächst die Lektüre folgender Quellen: [1], [2], [3] und [4].
Internes Backup
Auf dem Caipirinha-Server hatte ich zunächst viele Jahre lange einfach mit tar gesichert und dabei für Dokumente, Konfigurationsdateien und Projektdaten einzelne tar-, tgz- und tbz-Dateien erzeugt, und zwar Voll-Backups. Da sich nun aber auf dem Caipirinha-Server doch täglich einige Dateien ändern, bin ich nach einer längeren Durchsicht verschiedener Methoden darauf gekommen, Backups mit dar zu machen. dar funktioniert ähnlich wie tar, kann aber differentielle Backups machen. Aber betrachten wir zunächst einmal das Backup-Skript, welches über einen cron-Job jede Nacht ausgeführt wird:
/root/bin/backup_new.sh:
#!/bin/bash
# Automated backup script for important data on CAIPIRINHA
# Gabriel Rüeck, 20.09.2010
# Set appropriate umask.
umask 0077
# Create a directory for the backups if it does not already exist.
BACKUP_DIR='/backup/Backup-'$(date +%b)
test -d $BACKUP_DIR || mkdir $BACKUP_DIR
# Delete old backup directories.
find /backup -maxdepth 1 -daystart -mtime +62 -and -type d -name "Backup-*" -exec rm -rf {} \;
# Get the day of the month and determine whether full or incremental backups will be done. The first day will always result in a full backup.
DAY=$(date +%d)
if [ $DAY -eq 1 ]; then
# Do a full backup every beginning of a month.
dar -Q -R/home/public/Audio -c${BACKUP_DIR}/Audio-full -u"user.Beagle" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -D -R/home/public/Bilder -c${BACKUP_DIR}/Bilder-full -u"user.Beagle" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -D -R/home/public/Dokumente -c${BACKUP_DIR}/Dokumente-full -u"user.Beagle" -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" -P"c't" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -D -R/home/public/GroupOffice -c${BACKUP_DIR}/GroupOffice-full -u"user.Beagle" -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -D -R/home/public/Linux -c${BACKUP_DIR}/Linux-full -u"user.Beagle" -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" -X"*.iso" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -R/home/public/Mail -c${BACKUP_DIR}/Mail-full -u"user.Beagle" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -D -R/home/public/Software -c${BACKUP_DIR}/Software-full -u"user.Beagle" -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" -X"*.iso" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -D -R/home/public/Spiele -c${BACKUP_DIR}/Spiele-full -u"user.Beagle" -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" -X"fearcombat_en_*" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -D -R/home/public -c${BACKUP_DIR}/Rest-full -u"user.Beagle" -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" -P"Audio" -P"Bilder" -P"BitTorrent" -P"Datenbank*" -P"Dokumente" -P"GroupOffice" -P"Linux" -P"Mail" -P"Software" -P"Spiele" -P"Streaming" -P"Video" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -R/etc -c${BACKUP_DIR}/etc-full -u"user.Beagle" -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -R/srv/www/htdocs -c${BACKUP_DIR}/www-full -u"user.Beagle" -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" -P"mrtg" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -R/var/spool/cron/tabs -c${BACKUP_DIR}/cron_tables-full -u"user.Beagle" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -R/root -c${BACKUP_DIR}/root_files-full -u"user.Beagle" -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" -P".adobe" -P".strigi" -P".mozilla" -P".thumbnails" -P".tvbrowser" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -R/home -c${BACKUP_DIR}/user_files-full -u"user.Beagle" -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" -Z"*.mpg" -Z"*.avi" -Z"*.mkv" -P"ftp" -P"mailowner" -P"public" -P"tmp" -P"*/.adobe" -P"*/.strigi" -P"*/.google" -P"*/.mozilla" -P"*/.thumbnails" -P"*/.tvbrowser" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
# Check the integrity of the backup files.
dar -Q -t${BACKUP_DIR}/Audio-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/Bilder-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/Dokumente-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/GroupOffice-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/Linux-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/Mail-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/Software-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/Spiele-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/Rest-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/etc-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/www-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/cron_tables-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/root_files-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/user_files-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
else
# Do an incremental backup on all remaining days of the month.
dar -Q -R/home/public/Audio -c${BACKUP_DIR}/Audio-${DAY} -u"user.Beagle" -A${BACKUP_DIR}/Audio-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -D -R/home/public/Bilder -c${BACKUP_DIR}/Bilder-${DAY} -u"user.Beagle" -A${BACKUP_DIR}/Bilder-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -D -R/home/public/Dokumente -c${BACKUP_DIR}/Dokumente-${DAY} -u"user.Beagle" -A${BACKUP_DIR}/Dokumente-full -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" -P"c't" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -D -R/home/public/GroupOffice -c${BACKUP_DIR}/GroupOffice-${DAY} -u"user.Beagle" -A${BACKUP_DIR}/GroupOffice-full -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -D -R/home/public/Linux -c${BACKUP_DIR}/Linux-${DAY} -u"user.Beagle" -A${BACKUP_DIR}/Linux-full -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" -X"*.iso" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -R/home/public/Mail -c${BACKUP_DIR}/Mail-${DAY} -u"user.Beagle" -A${BACKUP_DIR}/Mail-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -D -R/home/public/Software -c${BACKUP_DIR}/Software-${DAY} -u"user.Beagle" -A${BACKUP_DIR}/Software-full -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" -X"*.iso" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -D -R/home/public/Spiele -c${BACKUP_DIR}/Spiele-${DAY} -u"user.Beagle" -A${BACKUP_DIR}/Spiele-full -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" -X"fearcombat_en_*" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -D -R/home/public -c${BACKUP_DIR}/Rest-${DAY} -u"user.Beagle" -A${BACKUP_DIR}/Rest-full -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" -P"Audio" -P"Bilder" -P"BitTorrent" -P"Datenbank*" -P"Dokumente" -P"GroupOffice" -P"Linux" -P"Mail" -P"Software" -P"Spiele" -P"Streaming" -P"Video" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -R/etc -c${BACKUP_DIR}/etc-${DAY} -u"user.Beagle" -A${BACKUP_DIR}/etc-full -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -R/srv/www/htdocs -c${BACKUP_DIR}/www-${DAY} -u"user.Beagle" -A${BACKUP_DIR}/www-full -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" -P"mrtg" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -R/var/spool/cron/tabs -c${BACKUP_DIR}/cron_tables-${DAY} -u"user.Beagle" -A${BACKUP_DIR}/cron_tables-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -R/root -c${BACKUP_DIR}/root_files-${DAY} -u"user.Beagle" -A${BACKUP_DIR}/root_files-full -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" -P".adobe" -P".strigi" -P".mozilla" -P".thumbnails" -P".tvbrowser" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -R/home -c${BACKUP_DIR}/user_files-${DAY} -u"user.Beagle" -A${BACKUP_DIR}/user_files-full -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" -Z"*.mpg" -Z"*.avi" -Z"*.mkv" -P"ftp" -P"mailowner" -P"public" -P"tmp" -P"*/.adobe" -P"*/.strigi" -P"*/.google" -P"*/.mozilla" -P"*/.thumbnails" -P"*/.tvbrowser" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
# Check the integrity of the backup files.
dar -Q -t${BACKUP_DIR}/Audio-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/Bilder-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/Dokumente-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/GroupOffice-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/Linux-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/Mail-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/Software-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/Spiele-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/Rest-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/etc-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/www-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/cron_tables-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/root_files-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/user_files-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
fi
# MySQL login information
readonly MYSQL_USERNAME='root'
readonly MYSQL_PASSWORD='geheimes_passwort'
# Create a directory for the database backups if it does not already exist.
MYSQL_BACKUP_DIR='/backup/MySQL-Backup_KW'$(date +%U)
test -d $MYSQL_BACKUP_DIR || mkdir $MYSQL_BACKUP_DIR
PGSQL_BACKUP_DIR='/backup'
# Delete old backup directories.
find /backup -maxdepth 1 -daystart -mtime +31 -and -type d -name "MySQL-Backup_KW*" -exec rm -rf {} \;
find /backup -maxdepth 1 -daystart -mtime +31 -and -type f -name "postgres_KW*" -exec rm {} \;
# Database backups will be done once per week, in the early morning of Sunday.
WEEKDAY=$(date +%u)
if [ $WEEKDAY -eq 7 ]; then
# Scan the MySQL Server for valid databases and create a dump file for each database found.
DATABASE_LIST=$(mysql -e 'show databases' -u$MYSQL_USERNAME -p$MYSQL_PASSWORD)
DATABASE_LIST=$(echo $DATABASE_LIST | cut -d " " -f2-)
for DATABASE in $DATABASE_LIST
for DATABASE in CCPM_Test PCBA nonCCPM_Test
do mysqldump -BC --hex-blob -u$MYSQL_USERNAME -p$MYSQL_PASSWORD $DATABASE | gzip -n9 | cat - > ${MYSQL_BACKUP_DIR}/${DATABASE}.sql.gz
done
# Backup the Postgres Server
su -l postgres -c "pg_dumpall -c | gzip -n9 | cat - > $PGSQL_BACKUP_DIR/postgres_KW$(date +%U).sql.gz"
fiAlle Backups werden auf eine separate Festplatte geschrieben, die als /backup eingebunden ist. Diese Festplatte befindet sich im Server selbst, und deswegen bietet ein Backup dorthin lediglich Schutz gegen Ausfall der Systemplatten oder versehentliches Löschen von Daten in den entsprechenden Verzeichnissen der Systemplatte, nicht aber gegen Blitzschlag, Sabotage oder Diebstahl der Maschine.
Nach dem Aufrufen werden zunächst die umask entsprechend gesetzt. Danach prüft das Skript, ob ein Verzeichnis /backup/Backup-xyz existiert, wobei xyz die Abkürzung des aktuellen Monatsnamens ist. Existiert ein solches Verzeichnis nicht, dann wird es erzeugt. Nun prüft das Skript, ob solche Verzeichnisse existieren, die älter als 62d sind. Diese werden allesamt gelöscht, denn auf der Backup-Festplatte ist natürlich nur begrenzt viel Platz. Der weitere Verlauf des Skripts hängt nun davon ab, ob der aktuelle Tag der erste Tag eines Monats ist.
Am ersten Tag eines Monats wird ein Voll-Backup gemacht,
an allen Folgetagen des Monats ein differentielles Backup; und zwar
differentiell zum Voll-Backup des Monatsanfangs. Dabei wird der dar-Befehl eingesetzt, dessen Optionen auf der man-Page (man dar) gut beschrieben sind. Einige Punkte sind hierbei hervorzuheben:
- Die Option -u”user.Beagle” bewirkt, dass die erweiterten Attribute jeder Datei, welche durch Beagle geändert worden sind, nicht berücksichtigt werden. Dies ist natürlich nur für diejenigen wichtig, die auch den Beagle-Dienst auf ihrem Linux-Server laufen haben. Dieser Suchdienst durchforstet periodisch alle Dateien in den eingestellten Verzeichnissen und legt seine Daten als erweitertes Attribut ab. Dadurch ändert sich jedes Mal die Datei, jedenfalls aus Sicht von dar, und wenn man die erweiterten Attribute nicht ausnimmt, kann es vorkommen, dass dar dann täglich ein Vollbackup macht, obwohl sich lediglich die Beagle-Informationen, nicht aber die Dateiinhalte geändert haben. Alles selbst erlebt.
- Am Ende jedes dar-Kommandos wird die Ausgabe von dar nach /dev/null
geschickt, denn das Skript soll im fehlerfreien Fall keine Ausgabe
erzeugen. Um aber festzustellen, ob ein Fehler aufgetreten ist und in
welcher Zeile des Skripts ein solcher Fehler aufgetreten ist, gibt es
die Sequenz “
[ $? -eq 0 ] || echo ...” nach jedem dar-Befehl. Das ist zwar nicht besonders elegant, dafür aber zweckmäßig. - Viele Verzeichnisse enthalten sowohl komprimierbare Dateien als auch Dateien, die bereits komprimiert sind (zip, jpg, tgz, …). Hier macht es Sinn, beim dar-Kommando die Option “-y” zu nutzen, dann aber für die entsprechenden Dateien die Komprimierung mit der Option “-Z” abzuschalten. Sonst verschwendet man nur Rechenzeit, weil dar versucht, eine bereits komprimierte Datei nochmals mit bzip2 zu komprimieren.
Nach den Backups wird die Integrität der Backup-Dateien geprüft.
An allen Folgetagen des Monats wird nur eine differentielle Sicherung durchgeführt, und zwar differentiell in Bezug auf die Sicherung vom Monatsanfang. Damit erreicht man an allen Folgetagen des Monats kürzere Backup-Zeiten. Zum nächsten Monatsanfang läßt man dann alle geänderten Dateien in ein neues Voll-Backup einfließen, und die differentiellen Backups werden dann wieder klein.
Danach kommt die Sicherung der MySQL– und der Postgres-Datenbanken. Die Datenbanken werden jeden Sonntag gesichert. Dieser Teil des Backup-Skripts folgt also einem anderen Rhythmus als der erste Teil mit den dar-Kommandos. Für die MySQL-Datenbanken wird zunächst ein Verzeichnis namens /backup/MySQL-Backup_KWxy erstellt, wobei xy die aktuelle Kalenderwoche ist. Existiert ein solches Verzeichnis nicht, dann wird es erzeugt. Alte Verzeichnisse werden nach einiger Zeit (31d) wieder gelöscht. Für die MySQL-Datenbanken wird eine Liste aller Datenbanken erstellt, jede Datenbank mit dem Kommando mysqldump ausgelesen, komprimiert und in dem zu der aktuellen Kalenderwoche gehörigen Verzeichnis abgelegt. Die Postgres-Datenbanken werden mit dem Befehl pg_dumpall ausgelesen, komprimiert und mit einem entsprechenden Namen, der die aktuelle Kalenderwoche beinhaltet, in /backup abgelegt. Da diese Sicherung als Benutzer postgres abläuft, muss das Verzeichnis /backup entweder für alle Benutzer beschreibbar sein, was ein gewisses Sicherheitsrisiko darstellt. Oder man erzeugt alternativ ein separates Verzeichnis in /backup, welches dem Benutzer postgres gehört und sichert die Dateien dort hinein.
Backup einer entfernten Maschine
Auf dem Caipirinha-Server werden auch Backups der entfernten Maschine rueeck.name erstellt. Dazu dient dieses Skript:
/root/bin/backup_1blu.sh:
#!/bin/bash
# Dieses Skript synchronisert wichtige Verzeichnisse des 1blu-Servers mit einem temporären Verzeichnis und erzeugt Backups.
# Gabriel Rüeck, 10.08.2010
readonly SOURCE='v37829.1blu.de'
readonly SYNCDIR='/backup/1blu/sync/'
# Wichtige Verzeichnisse synchronisieren
rsync -azq --rsh=ssh --delete --exclude="coppermine/" --exclude="mediawiki/" --exclude="mrtg/" --exclude="phpPgAdmin/" --exclude="webalizer/" ${SOURCE}:/srv/www/htdocs/ ${SYNCDIR}/srv/
rsync -azq --rsh=ssh --delete ${SOURCE}:/home/public/GroupOffice ${SYNCDIR}
rsync -azq --rsh=ssh --delete ${SOURCE}:/etc ${SYNCDIR}
rsync -azq --rsh=ssh --delete ${SOURCE}:/var/spool/cron/tabs ${SYNCDIR}
rsync -azq --rsh=ssh --delete ${SOURCE}:/root ${SYNCDIR}
# Set appropriate umask.
umask 0077
# Create a directory for the backups if it does not already exist.
BACKUP_DIR='/backup/1blu/dar/Backup-'$(date +%b)
test -d $BACKUP_DIR || mkdir $BACKUP_DIR
# Delete old backup directories.
find /backup/1blu/dar -maxdepth 1 -daystart -mtime +62 -and -type d -name "Backup-*" -exec rm -rf {} \;
# Get the day of the month and determine whether full or incremental backups will be done. The first day will always result in a full backup.
DAY=$(date +%d)
if [ $DAY -eq 1 ]; then
# Do a full backup every beginning of a month.
dar -Q -y -D -R${SYNCDIR}GroupOffice -c${BACKUP_DIR}/GroupOffice-full -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -R${SYNCDIR}etc -c${BACKUP_DIR}/etc-full -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -R${SYNCDIR}tabs -c${BACKUP_DIR}/cron_tables-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -R${SYNCDIR}root -c${BACKUP_DIR}/root_files-full -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" -P".adobe" -P".strigi" -P".mozilla" -P".thumbnails" -P".tvbrowser" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -R${SYNCDIR}srv -c${BACKUP_DIR}/srv_files-full -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
# Check the integrity of the backup files.
dar -Q -t${BACKUP_DIR}/GroupOffice-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/etc-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/cron_tables-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/root_files-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/srv_files-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
else
# Do an incremental backup on all remaining days of the month.
dar -Q -y -D -R${SYNCDIR}GroupOffice -c${BACKUP_DIR}/GroupOffice-${DAY} -A${BACKUP_DIR}/GroupOffice-full -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -R${SYNCDIR}etc -c${BACKUP_DIR}/etc-${DAY} -A${BACKUP_DIR}/etc-full -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -R${SYNCDIR}tabs -c${BACKUP_DIR}/cron_tables-${DAY} -A${BACKUP_DIR}/cron_tables-full >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -R${SYNCDIR}root -c${BACKUP_DIR}/root_files-${DAY} -A${BACKUP_DIR}/root_files-full -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" -P".adobe" -P".strigi" -P".mozilla" -P".thumbnails" -P".tvbrowser" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -y -R${SYNCDIR}srv -c${BACKUP_DIR}/srv_files-${DAY} -A${BACKUP_DIR}/root_files-full -Z"*.zip" -Z"*.bz2" -Z"*.gz" -Z"*.tgz" -Z"*.jpg" -Z"*.png" >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
# Check the integrity of the backup files.
dar -Q -t${BACKUP_DIR}/GroupOffice-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/etc-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/cron_tables-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/root_files-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
dar -Q -t${BACKUP_DIR}/srv_files-${DAY} >/dev/null; [ $? -eq 0 ] || echo 'In Zeile '$LINENO' ist ein Fehler aufgetreten!'
fi
# MySQL login information
readonly MYSQL_USERNAME='root'
readonly MYSQL_PASSWORD='geheimes_passwort'
# Create a directory for the database backups if it does not already exist.
MYSQL_BACKUP_DIR='/backup/1blu/mysql/Backup-KW'$(date +%U)
test -d $MYSQL_BACKUP_DIR || mkdir $MYSQL_BACKUP_DIR
PGSQL_BACKUP_DIR='/backup/1blu/pgsql'
# Delete old backup directories.
find /backup/1blu/mysql -maxdepth 1 -daystart -mtime +62 -and -type d -name "Backup-KW*" -exec rm -rf {} \;
find /backup/1blu/pgsql -maxdepth 1 -daystart -mtime +62 -and -type f -name "Backup-KW*" -exec rm {} \;
# Database backups will be done once per week, in the early morning of Sunday.
WEEKDAY=$(date +%u)
if [ $WEEKDAY -eq 7 ]; then
# Save MySQL databases
DATABASE_LIST=$(ssh ${SOURCE} "mysql -e 'show databases' -u$MYSQL_USERNAME -p$MYSQL_PASSWORD")
DATABASE_LIST=$(echo $DATABASE_LIST | cut -d " " -f2-) for DATABASE in $DATABASE_LIST
do ssh ${SOURCE} "mysqldump -BC --hex-blob -u${MYSQL_USERNAME} -p${MYSQL_PASSWORD} ${DATABASE} | gzip -n9" > ${MYSQL_BACKUP_DIR}/${DATABASE}.sql.gz
done
# Backup the Postgres Server
ssh ${SOURCE} "su -l postgres -c 'pg_dumpall -c | gzip -n9'" > $PGSQL_BACKUP_DIR/postgres_KW$(date +%U).sql.gz
fi
Dieses Skript ist ähnlich aufgebaut wie dasjenige im Abschnitt Backup#Internes_Backup. Zu Beginn des Skripts werden die zu sichernden Verzeichnisse der entfernten Maschine mit dem rsync-Kommando in ein lokales “Schattenverzeichnis” (/backup/1blu/sync/) synchronisiert. Das Sichern mit rsync hat mehrere Vorteile:
- rsync funktioniert gut über schwankende oder instabile Netzwerkverbindungen.
- Es werden immer nur die geänderten Dateien übermittelt.
- Die Übermittlung erfolgt verschlüsselt mit ssh.
Man kann erkennen, dass sich der Benutzer root des Caipirinha-Servers offensichtlich ohne Passwort als Benutzer root auf der Maschine v37829.1blu.de einloggen kann. Wie das funktioniert, ist beispielsweise in [5] und in [6] beschrieben. Danach werden die Unterverzeichnisse in /backup/1blu/sync/ mit dem Kommando dar nach dem gleichen Prinzip gesichert wie im Abschnitt Backup#Internes_Backup beschrieben. Danach folgen die Backups der Datenbanken MySQL und Postgres, deren Prinzip ebenfalls bereits beschrieben wurde. Neu ist lediglich, dass die entsprechenden Kommandos jetzt auf der entfernten Maschine v37829.1blu.de ausgeführt werden müssen und deshalb in entsprechende ssh ${SOURCE} "..."-Sequenzen eingesetzt werden müssen.
Dieses Prinzip funktioniert nur dann, wenn man es sich leisten kann, ein lokales Schattenverzeichnis zu bevorraten. Ist der Plattenplatz knapp, so muss man die elegantere Lösung wählen, einen externen Katalog des Voll-Backups durch dar erstellen zu lassen, an Hand dessen man dann gleich auf der entfernten Maschine ein differentielles Backup anstoßen kann, denn den Katalog kann man ja auf der entfernten Maschine bekannt machen. Diese Möglichkeit habe ich aber noch nicht ausprobiert.
Synchronisation mit einer entfernten Maschine
Wie es der Teufel so will, stirbt der Server zu Hause in der Wohnung, während man gerade in Urlaub weilt oder aus sonstigen Gründen nicht gleich Hand an die betroffene Maschine anlegen kann. Dagegen hilft nur, einen zweiten oder gar dritten Server in Betrieb zu halten, auf den regelmäßig gesichert wird und auf dem die gleichen Applikationen installiert sind. Dann kann man selbst im Urlaub noch schnell auf die andere Maschine “umschalten”. Eine solche Synchronisation wird beispielsweise zwischen den Maschinen caipirinha.homelinux.org, caipiroska.homelinux.org und rueeck.name durchgeführt, und zwar ebenfalls einmal pro Nacht. Das entsprechende Skript ist:
/root/bin/server_sync.sh:
#!/bin/bash
# Dieses Skript dient der Synchronisation des schwarzen Caipirinha-Servers mit dem blauen Caipirinha-Server und mit dem 1blu-Server
# Gabriel Rüeck, 10.08.2010
readonly BLU='v37829.1blu.de'
readonly CAIPIROSKA='caipiroska.homelinux.org'
readonly USER='Gabriel'
readonly RSYNC_PWD_FILE='/root/rsync_caipiroska.txt'
# Öffentliche Verzeichnisse synchronisieren
rsync -aq --rsh=ssh --delete /home/public/Bilder ${CAIPIROSKA}:/home/public/
rsync -azq --rsh=ssh --delete /home/public/Dokumente ${CAIPIROSKA}:/home/public/
rsync -azq --rsh=ssh --delete ${BLU}:/home/public/GroupOffice /home/public/
rsync -azq --rsh=ssh --delete ${BLU}:/home/public/Mail /home/public/
rsync -aq --rsh=ssh --delete /home/public/Mail-Indizierung ${CAIPIROSKA}:/home/public/
rsync -aq --rsh=ssh --delete /home/public/Software ${CAIPIROSKA}:/home/public/
rsync -aq --rsh=ssh --delete /home/public/Unterhaltung ${CAIPIROSKA}:/home/public/
# Webserver-Verzeichnisse synchronisieren
rsync -azq --rsh=ssh --delete ${BLU}:/srv/www/htdocs/coppermine /srv/www/htdocs/
#rsync -azv --rsh=ssh --delete ${BLU}:/srv/www/htdocs/groupoffice /srv/www/htdocs/
rsync -azq --rsh=ssh --delete ${BLU}:/srv/www/htdocs/mediawiki /srv/www/htdocs/
# Persönliche Verzeichnisse synchronisieren
rsync -azv --rsh=ssh --delete --exclude="nohup.out" --exclude=".*" /home/gabriel/ ${CAIPIROSKA}:/home/gabriel/
rsync -azv --rsh=ssh --delete --exclude="nohup.out" --exclude=".*" /home/joselia/ ${CAIPIROSKA}:/home/joselia/
# tmp- und dav-Ordner synchronisieren
unison caipiroska.prf
unison 1blu.prf
# Verzeichnisse über den rsyncd auf caipiroska synchronisieren
ssh ${CAIPIROSKA} '/etc/init.d/rsyncd start' >/dev/null
rsync -aq --delete --password-file=${RSYNC_PWD_FILE} /home/public/6502/ ${USER}@${CAIPIROSKA}::6502
rsync -aq --delete --password-file=${RSYNC_PWD_FILE} /home/public/Audio/ ${USER}@${CAIPIROSKA}::Audio
rsync -azq --delete --password-file=${RSYNC_PWD_FILE} /home/public/Bücher/ ${USER}@${CAIPIROSKA}::Bücher
rsync -azq --delete --password-file=${RSYNC_PWD_FILE} /home/public/Datenblätter/ ${USER}@${CAIPIROSKA}::Datenblätterrsync -aq --delete --password-file=${RSYNC_PWD_FILE} /home/public/Linux/ ${USER}@${CAIPIROSKA}::Linux
rsync -aq --delete --password-file=${RSYNC_PWD_FILE} /home/public/Spiele/ ${USER}@${CAIPIROSKA}::Spiele
ssh ${CAIPIROSKA} '/etc/init.d/rsyncd stop' >/dev/null
In diesem Skript werden Verzeichnisse zwischen den genannten drei Maschinen synchronisiert. Dabei kommen die Kommandos rsync für eine unidirektionale und unison für eine bidirektionale Synchronisation zum Einsatz. Des Weiteren wird rsync in zwei Betriebsarten eingesetzt:
- Remote Shell: In dieser Betriebsart (erster Block an rsync-Anweisungen) werden auf dem Quell- und auf dem Zielrechner je eine rsync-Instanz gestartet. Die Datenübertragung erfolgt durch eine gesicherte Verbindung (ssh). Dieser Modus ist geeignet für Daten, die auch auf ihrem Übertragungsweg nicht abgefangen werden dürfen, weil sie vertraulich sind.
- Rsync-Dämon: In dieser Betriebsart hat entweder der Quell- oder der Zielrechner einen rsync-Dienst (üblicherweise auf Port 873) aktiv. Dieser Dienst beinhaltet eine Konfigurationsdatei, in der Verzeichnisse aufgeführt sind. Mit diesen Verzeichnissen kann synchronisiert werden. Die Anmeldung ist zwar verschlüsselt, der Datentransfer aber nicht mehr. Diese Art der Synchronisation eignet sich also nur für Daten, die auch mitgelesen werden können, weil sie keine vertraulichen Informationen enthalten. Der Vorteil ist, dass wegen der fehlenden Verschlüsselung weniger Maschinenlast erzeugt wird.
Die hier zum Einsatz kommende Konfigurationsdatei des rsync-Dienstes sieht so aus:
/etc/rsyncd.conf:
log file = /var/log/rsyncd.log log format = %h %o %f %l %b max connections = 4 pid file = /var/run/rsyncd.pid read only = false slp refresh = 300 timeout = 600 transfer logging = true uid = gabriel use chroot = true use slp = false [6502] path = /home/public/6502 auth users = Gabriel secrets file = /etc/rsyncd.secrets gid = users [Audio] path = /home/public/Audio auth users = Gabriel secrets file = /etc/rsyncd.secrets gid = relationship [Bücher] path = /home/public/Bücher auth users = Gabriel secrets file = /etc/rsyncd.secrets gid = users [Datenblätter] path = /home/public/Datenblätter auth users = Gabriel secrets file = /etc/rsyncd.secrets gid = users [Linux] path = /home/public/Linux auth users = Gabriel secrets file = /etc/rsyncd.secrets gid = users [Spiele] path = /home/public/Spiele auth users = Gabriel secrets file = /etc/rsyncd.secrets gid = users
In der Datei /etc/rsyncd.secrets sind alle zulässigen Benutzer des rsync-Dienstes und deren Passwort im Klartext ausgeführt. Deshalb darf diese Datei nur für root lesbar sein. Es muss auch klar sein, dass man eben deswegen auf keinen Fall das System-Passwort verwenden darf.
Auch für unison werden Konfigurationsdateien benötigt, nämlich die beiden hier im Skript angegebenen Dateien /root/.unison/caipiroska.prf und /root/.unison/1blu.prf, welche die Verzeichnisse festlegen, die zwischen den beteiligten Maschinen bidirektional synchronisiert werden sollen. Sie sehen so aus:
/root/.unison/caipiroska.prf:
# Synchronisation zwischen CAIPIRINHA und CAIPIROSKA root = ssh://caipiroska.homelinux.org//home/ root = /home/ sshargs = -C -o ConnectTimeout=300 fastcheck = yes maxthreads = 1 perms = -1 batch = true silent = true owner = true group = true logfile = /var/log/unison # Prioirität festlegen prefer = /home/ # Zu synchronisierende Pfade path = tmp ignore = Path tmp/Blue-Ray/*
/root/.unison/1blu.prf:
# Synchronisation zwischen CAIPIRINHA und 1BLU root = ssh://rueeck.name//home/public/ root = /home/public/ sshargs = -C -o ConnectTimeout=300 fastcheck = yes maxthreads = 1 perms = -1 batch = true silent = true owner = true group = true logfile = /var/log/unison # Prioirität festlegen prefer = ssh://rueeck.name//home/public/ # Zu synchronisierende Pfade path = Dropbox ignore = Name .*
Durch das Sichern auf externe Maschinen verschafft man sich einen Schutz gegen Feuer-, Wasser-, Kriegsschäden und gegen einen möglichen Diebstahl des Servers. Ein Saboteur, dem ein Einloggen als root auf einer der Maschinen gelingt, könnte wegen der automatischen Synchronisation aber weiterhin alle Daten sabotieren. Dagegen hilft wirklich nur ein Backup auf eine externe Festplatte, die nach dem Backup von der Maschine getrennt und sicher verwahrt wird. Eine solche externe Festplatte sollte natürlich (wie auch die Server-Platten) verschlüsselt sein, und idealerweise hat man mehrere davon, so dass man immer noch ein Backup zur Verfügung hat, wenn beim Sichern gerade der Blitz in den Server und die angeschlossene externe Festplatte schlägt und alles futsch ist.
Apache
Einführung
Der Apache-Webserver ist ein zentrales Element des Caipirinha-Servers, weil auf ihm aufbauend noch zahlreiche weitere Dienste realisiert sind, und zwar:
- Caipigallery auf [1]
- Caipiwiki auf [2]
- GroupOffice auf [3]
- Caipithek auf [4]
- MRTG für die verschiedenen Grafiken auf [5], [6], [7], [8]
- USV-Status auf [9]
Pakete
Zum Betrieb des Apache-Webservers müssen die folgenden Pakete auf dem Caipirinha-Server installiert werden. Außerdem muss PHP installiert und konfiguriert worden sein. Als Einstieg in die Konfiguration des Apache-Webservers ist ferner das Buch [10] sehr empfehlenswert.
- apache2
- apache2-doc
- apache2-mod_perl
- apache2-mod_php5
- apache2-prefork
- apache2-utils
- susehelp
- susehelp_de
- susehelp_en
Basis-Setup
Um Apache auf die eigenen Anforderungen anzupassen, erstellen wir zunächst eine Konfigurationsdatei, die dann zusätzlich zu den bereits existierenden Konfigurationsdateien beim Start des Apache-Servers abgearbeitet wird:
/etc/apache2/httpd.conf.local:
#
# Additional Configuration for the Apache Web server on CAIPIRINHA
#
# Gabriel Rüeck, 24.10.2010
AddDefaultCharset UTF-8
DirectoryIndex index.shtml
# Additional Handler Declarations
AddHandler imap-file map
SSLCipherSuite HIGH
# Verzeichnisse freigeben außerhalb des DocumentRoot
Alias /kde-icons /opt/kde3/share/icons/crystalsvg/48x48/mimetypes
Alias /gnome-icons /usr/share/icons/gnome/32x32
Alias /dav /home/public/Dropbox
# Umleitungen auf die neu angemietete Domain rueeck.name
Redirect permanent /coppermine http://rueeck.name/coppermine
#Redirect /mediawiki http://rueeck.name/mediawiki
Redirect permanent /lx-erp https://rueeck.name/lx-erp
Redirect permanent /phpPgAdmin https://rueeck.name/phpPgAdmin
Redirect permanent /groupoffice https://rueeck.name/groupoffice
# KDE ICONS (needed for update_rss.sh)
<Location /kde-icons>
Allow from all
</Location>
# GNOME ICONS (needed for caipithek.php)
<Location /gnome-icons>
Allow from all
</Location>
# MULTIMEDIA-VERZEICHNIS
<Directory /srv/www/htdocs/MM>
SSLRequireSSL
AuthName "Secure Access on CAIPIRINHA"
AuthType Digest
AuthUserFile /srv/www/htdocs/MM/.htpasswd
Require valid-user
Options Indexes FollowSymLinks
IndexOptions +IgnoreCase +FoldersFirst +VersionSort +Charset=UTF-8
</Directory>
# DIGITAL DROPBOX
<Directory /srv/www/htdocs/Dropbox>
AuthName "Digital Dropbox on caipirinha"
AuthType Digest
AuthUserFile /home/public/Dropbox/.htpasswd
Require valid-user
</Directory>
# WEBALIZER
<Directory /srv/www/htdocs/webalizer>
AuthName "Secure Access on CAIPIRINHA"
AuthType Digest
AuthUserFile /srv/www/htdocs/MM/.htpasswd
Require valid-user
</Directory>
# LX-OFFICE
<Directory /srv/www/htdocs/lx-office-erp>
SSLRequireSSL
</Directory>
<Directory /srv/www/htdocs/lx-erp>
SSLRequireSSL
Options ExecCGI Includes FollowSymlinks
</Directory>
<Directory /srv/www/htdocs/lx-erp/users>
Deny from all
</Directory>
<Directory /srv/www/htdocs/phpPgAdmin>
SSLRequireSSL
</Directory>
# WEBDAV WEBFOLDERS
# Speicherort für Lock-Datenbank
DAVLockDB /var/lock/dav/lock
DavDepthInfinity off
<Location /dav>
Allow from all
Dav on
ForceType text/plain
AuthType Digest
AuthName "Secure Access on CAIPIRINHA"
AuthUserFile /srv/www/htdocs/MM/.htpasswd
<LimitExcept OPTIONS>
Require valid-user
</LimitExcept>
Options Indexes
IndexOptions +IgnoreCase +FoldersFirst +VersionSort +Charset=UTF-8
SSLRequireSSL
</Location>
Gehen wir diese Konfiguration einmal Schritt für Schritt durch:
- Mit AddDefaultCharset wird UTF-8 als Standard-Zeichensatz des Webservers eingestellt. Dadurch können auch Texte in nicht-lateinischen Buchstaben problemlos dargestellt werden. Heutzutage macht wegen der zunehmenden Internationalisierung eigentlich auch keine andere Einstellung mehr Sinn.
- Mit DirectoryIndex legt man fest, dass Webseiten mit Namen index.shtml ebenfalls als Index-Seiten (also so wie index.html) betrachtet werden. Manche Entwicklungswerkzeuge für Webseiten nehmen die Endung shtml für Webseiten, welche Server Side Includes (SSI) enthalten.
- In der Zeile mit der Direktive AddHandler wird nun ein Handler für Image Maps benannt.
- Die folgende Direktive SSLCipherSuite fordert den Einsatz von Triple-DES-Verschlüsselung beim Aufruf verschlüsselter Webseiten (https) und verbietet den Einsatz schwächerer Verschlüsselungsalgorithmen.
- Nun werden Alias-Pfade für einige Verzeichnisse außerhalb des DocumentRoot festgelegt. Damit erreicht man quasi eine “Umleitung” des Zugriffs. So wird beispielsweise beim Aufruf der Seite http://caipirinha.homelinux.org/dav nicht etwa in das Verzeichnis /srv/www/htdocs/dav verzweigt, wie dies normalerweise der Fall wäre, sondern der Webserver sieht stattdessen in /home/public/Dropbox nach. Mit dieser Methode kann man beliebige Verzeichnisse einbinden, ohne dass sich alles unterhalb des DocumentRoot (/srv/www/htdocs) befinden muss.
- Nun folgen einige Umleitungen für Webseiten, die vormals auf dem Caipirinha-Server gehostet wurden und die jetzt auf die Maschine rueeck.name verschoben worden sind. Damit Zugriffe auf diese vormals auf dem Caipirinha-Server existierenden Seiten nicht ins Leere gehen, werden sie automatisch umgeleitet.
- Die folgenden beiden Location-Direktiven haben als einzigen Zweck das Zulassen des Zugriffs für alle Clients auf die Web-Verzeichnisse:
- Die folgende Directory-Direktive bezieht sich auf das Verzeichnis /srv/www/htdocs/MM (erreichbar über https://10.130.25.50/MM). Dieses Verzeichnis ist erfordert zwingend eine verschlüsselte Verbindung (https) und eine erfolgreiche Authentifizierung (Direktiven SSLRequireSSL, AuthName, AuthType, AuthUserFile, Require) mit einem gültigen Paar aus Benutzernamen und Passwort aus der Datei /srv/www/htdocs/MM/.htpasswd. Außerdem ist bei diesem Verzeichnis das Auflisten des Verzeichnis-Inhalts (Indexes) zulässig. Bei der Auflistung werden bestimmte Sortierkriterien eingehalten, die zusätzlich (deswegen das “+”-Zeichen) zu den Default-Optionen aktiviert werden (+IgnoreCase +FoldersFirst +VersionSort). Außerdem wird das Listing mit dem Zeichensatz UTF-8 durchgeführt (+Charset=UTF-8).
- Dann folgt eine Directory-Direktive für die Dropbox, bei der ebenfalls eine Authentifizierung, aber keine Verschlüsselung notwendig ist.
- Eine vergleichbare Konfiguration hat die nächste Directory-Direktive, welche den Zugriff auf die Webserver-Statistiken in /srv/www/htdocs/webablizer regelt (siehe Webalizer).
- Dann folgen drei Abschnitte, welche den Zugriff auf die Dateien für das Paket lx-office regeln. Dabei ist zu beachten, dass für das Verzeichnis /srv/www/htdocs/lx-erp spezifische Optionen festgelegt werden, und zwar nicht zusätzlich zu den Default-Optionen, sondern anstatt der Default-Optionen. Deshalb fehlt hier das “+”-Zeichen, welches bei der Festlegung der Optionen in einem der vorherigen Blöcke benutzt worden war. Für den Zugriff auf lx-office sowie auf phpPgAdmin ist zwingend Verschlüsselung notwendig, weil bei der Benutzung dieser Pakete Passworte übertragen werden müssen.
- Zuletzt kommen die Einstellungen für das WebDAV-Verzeichnis in /home/public/Dropbox (erreichbar über https://caipirinha.homelinux.org/dav). Eine Einführung in WebDAV findet sich auf [11], [12], [13] und [14]; die detaillierte Spec gibt es auf [15]. Bei der Konfiguration von WebDAV sind mehrere Punkte zu beachten:
- Zunächst muss eine lock-Datenbank eingerichtet werden, welche im Betrieb dann mehrere Dateien (in diesem Fall lock.dir und lock.pag) erzeugt. Dazu muss das Verzeichnis /var/lock/dav erzeugt werden und dem Apache-Benutzer wwwrun:www gehören; das macht man mit den beiden Befehlen unten.
- Mit der Direktive DavDepthInfinity werden PROPFIND-Abfragen mit unendlicher Tiefe ausgeschaltet. Dies wäre bei meinem kleinen Anwenderkreis allerdings nicht unbedingt notwendig gewesen.
- Für den Zugriff auf https://caipirinha.homelinux.org/dav ist eine verschlüsselte Verbindung und eine Authentifizierung des Typs Digest notwendig. Digest muss deswegen gewählt werden, weil Windows Vista und Windows 7-Clients eine Authentifizierung mit Basic nicht mehr durchführen. Beim Authentifizierungstyp Basic wird das Passwort nicht verschlüsselt, sondern im Base64-Verfahren übertragen und lässt sich daher beim Mitschneiden der Verbindung problemlos abschöpfen. Zwar ist dies bei einer gesicherten (https)-Verbindung kein großes Problem, aber moderne Windows-Clients fordern das eben, und die Grundidee ist ja auch richtig.
- Die Authentifizierung wird allerdings nicht für die Methode OPTIONS gefordert, mit welcher ein Client eine Liste der unterstützten HTTP-Methoden anfordern kann. Der Grund für diese Einstellung ist, dass ich in den Log-Dateien des Servers viele Fehler gefunden habe, welche daraus resultieren, dass Windows Vista- und Windows 7-Clients immer zunächst ohne Authentifizierung auf den WebDAV-Server zugreifen wollen. Eine große Anzahl der Anfragen geht dabei von den Methoden OPTIONS und PROPFIND aus. PROPFIND hatte ich testweise ebenfalls von der Authentifizierung ausgenommen (mit der LimitExcept-Direktive), aber dann konnte jeder Client auch ohne Authentifizierung den Verzeichnisinhalt von /home/public/Dropbox auflisten lassen. Ein Zugriff auf die Dateien war zwar nicht möglich, aber dennoch schien mir dies aus Gründen der Sicherheit problematisch zu sein.
mkdir /var/lock/dav chown wwwrun:www /var/lock/dav
Die Einstellungen für den WebDAV-Betrieb können sicherlich verbessert werden, und für entsprechende Vorschläge bin ich daher dankbar.
In dieser Konfigurationsdatei sind die Dateien /srv/www/htdocs/MM/.htpasswd und /home/public/Dropbox/.htpasswd
referenziert, welche gültige Paare aus einem Benutzernamen und dem
dazugehörigen verschlüsselten Passwort enthalten. Eine solche Datei wird
mit dem Befehl htdigest2 erzeugt, dessen Benutzung in man htdigest2 beschrieben ist. Möchte man beispielsweise noch einen Benutzer alfred hinzufügen, so würde man eingeben:
htdigest2 /srv/www/htdocs/MM/.htpasswd "Secure Access on CAIPIRINHA" alfred
und bei der darauf folgenden Abfrage ein Passwort eingeben. Der Wert für realm (siehe man htdigest2)
sollte gleich dem Ausdruck (hier: “Secure Access on CAIPIRINHA”) sein,
welcher im entsprechenden Abschnitt der Konfigurationsdatei /etc/apache2/httpd.conf.local bei der Direktive AuthName eingetragen ist.
Nun muss noch eine weitere Konfigurationsdatei angepasst werden. In der Datei /etc/apache2/mod_mime-defaults.conf werden folgende Änderungen (Entfernen des davor stehenden “#”) vorgenommen:
- Der MIME-Typ für *.tgz-Dateien wird gesetzt.
- Der Filter für Server Side Includes (SSI) wird aktiviert.
/etc/apache2/mod_mime-defaults.conf:
... # # AddType allows you to add to or override the MIME configuration # file mime.types for specific file types. # AddType application/x-tar .tgz ... # # Filters allow you to process content before it is sent to the client. # # To parse .shtml files for server-side includes (SSI): # (You will also need to add "Includes" to the "Options" directive.) # AddType text/html .shtml AddOutputFilter INCLUDES .shtml ...
Mit YaST2 müssen jetzt mit dem Editor für /etc/sysconfig noch einige Variablen richtig gesetzt werden:
- Applications→SuSEhelp→DOC_HOST wird auf caipirinha.homelinux.org gesetzt.
- Applications→SuSEhelp→DOC_ALLOW bleibt leer.
- Applications→SuSEhelp→DOC_AUTOINDEX wird auf yes gesetzt.
- Network→WWW→Apache→SuSEhelp→DOC_SERVER wird auf yes gesetzt.
- Network→WWW→Apache2→APACHE_CONF_INCLUDE_FILES wird auf /etc/apache2/httpd.conf.local gesetzt, damit unsere Konfigurationsdatei von oben überhaupt verarbeitet wird.
- Network→WWW→Apache2→APACHE_CONF_INCLUDE_DIRS bleibt leer.
- Network→WWW→Apache2→APACHE_MODULES muss mindestens die Module actions alias auth_basic auth_digest authn_file authz_host authz_default authz_user autoindex cgi charset_lite dav dav_fs dav_lock deflate dir env expires imagemap include log_config mime mime_magic negotiation setenvif suexec ssl userdir php5 beinhalten.
- Network→WWW→Apache2→APACHE_SERVER_FLAGS wird auf -D SSL gesetzt, um SSL zu aktivieren.
- Network→WWW→Apache2→APACHE_HTTPD_CONF bleibt leer.
- Network→WWW→Apache2→APACHE_MPM bleibt leer.
- Network→WWW→Apache2→APACHE_SERVERADMIN wird auf root@caipirinha.homelinux.org eingestellt.
- Network→WWW→Apache2→APACHE_SERVERNAME wird auf caipirinha.homelinux.org eingestellt.
- Network→WWW→Apache2→APACHE_START_TIMEOUT wird auf 20 gestellt.
- Network→WWW→Apache2→APACHE_SERVERSIGNATURE wird auf on gesetzt.
- Network→WWW→Apache2→APACHE_LOGLEVEL wird auf warn gesetzt.
- Network→WWW→Apache2→APACHE_ACCESS_LOG wird auf /var/log/apache2/access_log combined gesetzt.
- Network→WWW→Apache2→APACHE_USE_CANONICAL_NAMES wird auf off gesetzt.
- Network→WWW→Apache2→APACHE_SERVERTOKENS wird auf OS gesetzt.
- Network→WWW→Apache2→APACHE_EXTENDED_STATUS wird auf off gesetzt.
Die hier genannten Einstellungen finden sich dann auch in den System-Dateien:
- /etc/sysconfig/susehelp
- /etc/sysconfig/apache2
SSL-Setup

Für den erfolgreichen SSL-Betrieb sind noch weitere Konfigurationen erforderlich. Zunächst muss die Datei /etc/apache2/vhosts.d/vhost-ssl.template in /etc/apache2/vhosts.d/vhost.conf umbenannt werden. Alternativ kann man natürlich eine Kopie mit diesem Namen erstellen. An dieser Datei braucht nichts weiter geändert zu werden. Diese Datei erstellt zusammen mit der oben beschriebenen Option “-D SSL” einen virtuellen Server, der auf Port 443 “hört” und darüber die verschlüsselte Kommunikation abwickelt.
Nun muss noch ein Zertifikat für den SSL-Betrieb des Servers erstellt werden. Es ist ratsam, zunächst eine Einführung zu diesem Thema zu lesen, beispielsweise [16] oder [17]. Dazu existieren im Wesentlichen drei Herangehensweisen:
Einfaches Server-Zertifikat

Die Vorgehensweise ist in [18] hinreichend beschrieben. Es genügt eine openssl-Sequenz
mit einigen Angaben zum Server, und das Schlüsselpaar wird erstellt.
Dann muss man nur noch die Rechte des öffentlichen Zertifikats anpassen
und die Schlüssel in die entsprechenden Verzeichnisse verschieben,
nämlich:
- server.crt nach /etc/apache2/ssl.crt/
- server.key nach /etc/apache2/ssl.key/
caipirinha:~/tmp # openssl req -new -x509 -nodes -out server.crt -keyout server.key Generating a 1024 bit RSA private key ........++++++ .......................++++++ writing new private key to 'server.key' ----- You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ----- Country Name (2 letter code) [AU]:DE State or Province Name (full name) [Some-State]:Berlin Locality Name (eg, city) []:Berlin Organization Name (eg, company) [Internet Widgits Pty Ltd]:Gabriel Rüeck Organizational Unit Name (eg, section) []: Common Name (eg, YOUR name) []:caipirinha.homelinux.org Email Address []:administrator@caipirinha.homelinux.org caipirinha:~/tmp # chmod a+r server.crt caipirinha:~/tmp # mv server.crt /etc/apache2/ssl.crt/ caipirinha:~/tmp # mv server.key /etc/apache2/ssl.key/
Selbstsigniertes Server-Zertifikat

Die Vorgehensweise ist in [https//caipirinha.homelinux.org/manual/ssl/ssl_faq.html#ownca] hinreichend beschrieben. Mit diesem Verfahren sagt man den Benutzern seines Servers eigentlich: “Ich habe dieses Zertifikat erzeugt, und ich beglaubige auch, dass ich es selbst erzeugt habe und dass alles so stimmt.” Dies ist natürlich eine gewagte Behauptung, und weil das im Prinzip jeder so machen kann, gibt es üblicherweise beim Aufruf der SSL-verschlüsselten Seite eine Fehlermeldung, so wie im Bild Problem mit dem Sicherheitszertifikat. Mit dieser Fehlermeldung weist der Browser darauf hin, dass keine der bekannten und vertrauenswürdigen Beglaubigungsstellen dieses Zertifikat überprüft hat und dass hier etwas “faul” ist. Man kann dann zwar auf den Link “Laden dieser Webseite fortsetzen (nicht empfohlen)” klicken, und man kommt dann schließlich zur Webseite wie im Bild Zertifikatsfehler. Allerdings bleibt das URL-Fenster im Browser rot hinterlegt, und wenn man auf Zertifikatsfehler klickt, bekommt man auch den Grund dafür angezeigt.
Nichtsdestotrotz ist ein selbstsigniertes Zertifikat für private Server eine nützliche Sache, denn ein solches Zertifikat kann man kostenlos erstellen. Gibt es nur wenige Benutzer des eigenen Servers, dann kann man diesen Benutzern vielleicht sogar beibringen, das selbstsignierte Zertifikat dauerhaft im Browser zu installieren. Dazu führt man ausgehend vom Bild Zertifikatsfehler nacheinander folgende Schritte aus:
- Auf “Zertifikate anzeigen” klicken.
- Auf “Zertifikat installieren” klicken.
- “Alle Zertifikate in folgendem Speicher speichern” auswählen und als Speicherort “Vertrauenswürdige Stammzertifizierungsstellen” auswählen, so wie im Bild Zertifikatsimport-Assistent gezeigt.
- Den Fingerabdruck des Zertifikats überprüfen (Bild Fingerabdruck des Zertifikats).
- Das Einfügen des Zertifikats durch mehrmaliges Bestätigen von “Ja” oder “OK” abschließen.

Woher weiß man, ob der angezeigte Fingerabdruck wirklich der richtige ist? Es könnte sich ja um einen Man-in-the-middle-Angriff handeln? Um hier sicher zu gehen, muss der Administrator des Servers den wahren Fingerabdruck auf sonstigen geschützten Wegen an seine Benutzer übermitteln oder eben das Risiko eingehen, dass seine Benutzer das Zertifikat installieren, ohne dass sie gründlich prüfen. Man sieht also schon, dass ein selbstsigniertes Zertifikat keine Lösung für einen Server mit kommerziellen Anwendungen ist.
In meinem Fall betreibe ich selbst drei Server, welche auch SSL-Verbindungen unterstützen. Ich habe allerdings nur ein Root-Zertifikat im Rahmen der OpenVPN-Konfiguration erzeugt, mit dem ich dann die jeweiligen Server-Zertifikate signiert habe. Dazu habe ich aber komplett die Skripte aus dem OpenVPN-Paket benutzt.
Fremdsigniertes Server-Zertifikat
Ein fremdsigniertes Zertifikat ist erforderlich, wenn man seinen Server im SSL-Betrieb einer größeren Allgemeinheit zugänglich machen will und seine Benutzer nicht mit Meldungen über Zertifikatsfehler abschrecken will. Dazu erzeugt man nach der in [19] beschriebenen Vorgehensweise einen sogenannten Certificate Signing Request (CSR), den man dann einer vertrauenswürdigen Zertifizierungsstelle zur Signierung zusendet. Die Signaturstelle verlangt meistens noch mehr Information, um prüfen zu können, ob der Antragsteller auch wirklich existiert und tatsächlich einen Server unter dem Namen unterhält, unter dem er den CSR erstellt hat. Dies ist aufwändig und kostet daher auch Geld. Die Preise sind aber unterschiedlich; ein Vergleich lohnt sich daher vor Abschluss eines entsprechenden Vertrags. Mit einem fremdsignierten Server-Zertifikat gibt es dann idealerweise keine Probleme mehr beim Aufrufen der SSL-geschützten Seite durch den Benutzer.
Virtueller Server
Man kann auf einer Maschine auch mehrere, voneinander unabhängige Webangebote hosten, und das mit einem Apache-Server. Das nennt sich “virtuelles Hosting”. Webhoster nutzen beispielsweise dieses Prinzip, um vielen Kunden eine eigene Domain anzubieten, wobei meist ganz viele Domains auf eine IP-Adresse abgebildet werden. Diese Webseiten liegen dann oft auch auf einer leistungsfähigen Maschine. Das schont Ressourcen und spart Geld, denn für eine private Webseite braucht man nicht unbedingt einen eigenen Root- Server. Man unterscheidet dabei zwischen IP-basiertem virtuellem Hosting und namensbasiertem virtuellem Hosting [20]. Das folgende Beispiel beschreibt das namensbasierte virtuelle Hosting [21], welches auf dem Caipiroska-Server verwirklicht wurde. Dort gibt es folgende Domains:
Zu beachten ist, dass alle drei Domains auf derselben Maschine liegen und die gleiche IP-Adresse haben. Beim Aufruf einer drei Domains übermittelt der Client-Browser in seiner Anfrage an den Webserver den Namen der Domain, die er aufrufen will (RFC2616, für SSL außerdem RFC4366). Der Server greift dann in die “richtige Kiste” und liefert das gewünschte Webangebot aus. Beim Caipiroska-Server sind die Domains allerdings nicht völlig voneinander getrennt, sondern es existiert vielmehr eine Matrix-Struktur, so wie hier dargestellt:
| http://caipiroska.homelinux.org https://caipiroska.homelinux.org | http://hle.homelinux.org https://hle.homelinux.org | http://ba-berlin.homelinux.org https://ba-berlin.homelinux.org | Unterseite |
|---|---|---|---|
| Webangebot der Domain caipiroska.homelinux.org Daten stammen aus /srv/www/htdocs/caipiroska | Webangebot der Domain hle.homelinux.org Daten stammen aus /srv/www/htdocs/hle | Webangebot der Domain ba-berlin.homelinux.org Daten stammen aus /srv/www/htdocs/ba-berlin | / |
| Persönliche Seite des Benutzers Gabriel Daten stammen aus /home/gabriel/public_html | Persönliche Seite des Benutzers Gabriel Daten stammen aus /home/gabriel/public_html | Persönliche Seite des Benutzers Gabriel Daten stammen aus /home/gabriel/public_html | /~gabriel |
| ERP-System (LX-Office) installiert in /srv/www/htdocs/lx-office-erp | ERP-System (LX-Office) installiert in /srv/www/htdocs/lx-office-erp | ERP-System (LX-Office) installiert in /srv/www/htdocs/lx-office-erp | /lx-erp |
| CPU-Last des Caipiroska-Servers Daten stammen aus /srv/www/htdocs/mrtg | CPU-Last des Caipiroska-Servers Daten stammen aus /srv/www/htdocs/mrtg | CPU-Last des Caipiroska-Servers Daten stammen aus /srv/www/htdocs/mrtg | /mrtg/cpu.html |
| USV-Status meiner Server Daten werden über ein CGI-Skript erzeugt | USV-Status meiner Server Daten werden über ein CGI-Skript erzeugt | USV-Status meiner Server Daten werden über ein CGI-Skript erzeugt | /cgi-bin/multimon.cgi |
| Statistiken der Domain caipiroska.homelinux.org Daten stammen aus /srv/www/htdocs/caipiroska/webalizer | Statistiken der Domain hle.homelinux.org Daten stammen aus /srv/www/htdocs/hle/webalizer | Statistiken der Domain ba-berlin.homelinux.org Daten stammen aus /srv/www/htdocs/ba-berlin/webalizer | /webalizer |
Eine solche Mischung aus getrenntem Inhalt und gemeinsamem Inhalt würde man natürlich nicht zulassen, wenn man einen professionellen Webhosting-Dienst hochziehen wollte. Insofern sind die hier abgedruckten Konfigurationsdateien eher zur Anregung eigener Ideen denn als Musterbeispiel namensbasierter Virtualisierung zu verstehen:
/etc/apache2/httpd.conf.local:
# # Konfiguration für den CAIPIROSKA-Server # # Gabriel Rüeck, 20.10.2010 AddDefaultCharset UTF-8 DirectoryIndex index.shtml # Additional Handler Declarations AddHandler imap-file map SSLCipherSuite HIGH # LINKS, DIE FÜR ALLE VHOSTS GELTEN SOLLEN Alias /lx-erp /srv/www/htdocs/lx-office-erp Alias /kde-icons /opt/kde3/share/icons/crystalsvg/48x48/mimetypes Alias /gnome-icons /usr/share/icons/gnome/32x32 Alias /mrtg/ /srv/www/htdocs/mrtg/ # VERZEICHNIS-REGELN <Directory /srv/www/htdocs/hle> Order deny,allow Deny from all Allow from 213.61.59.192/27 Allow from 213.61.250.32/29 Allow from 213.61.250.38/31 </Directory> <Directory /home/shared> Order deny,allow Deny from all Allow from 213.61.59.192/27 Allow from 213.61.250.32/29 Allow from 213.61.250.38/31 Options FollowSymLinks </Directory> <Directory /srv/www/htdocs/hle/bugzilla> AddHandler cgi-script .cgi Options +Indexes +ExecCGI DirectoryIndex index.cgi AllowOverride Limit </Directory> # WEBALIZER <Location /webalizer> AuthName "Secure Access on CAIPIRINHA" AuthType Digest AuthUserFile /srv/www/htdocs/caipiroska/MM/.htpasswd Require valid-user </Location> # KDE ICONS (needed for update_rss.sh) <Location /kde-icons> Allow from all </Location> # GNOME ICONS (needed for caipithek.php) <Location /gnome-icons> Allow from all </Location> # LX-OFFICE <Directory /srv/www/htdocs/lx-office-erp> SSLRequireSSL </Directory> <Directory /srv/www/htdocs/lx-erp> SSLRequireSSL Options ExecCGI Includes FollowSymlinks </Directory> <Directory /srv/www/htdocs/lx-erp/users> Deny from all </Directory> <Directory /srv/www/htdocs/phpPgAdmin> SSLRequireSSL </Directory>
Viele Direktiven dieser Konfiguration wurden bereits im Abschnitt Basis-Setup beschrieben, und deshalb sollen nur noch neue Konfigurationen erläutert werden:
- Das Verzeichnis /srv/www/htdocs/hle soll nur aus bestimmten IP-Adreßbereichen zugänglich sein. Deswegen wurde der Zugriff in der entsprechenden Directory-Direktive zunächst für alle gesperrt und dann selektiv für einige Netzwerke zugelassen.
- Für das Verzeichnis /home/shared gilt ebenfalls das eben Gesagte.
- Für das Verzeichnis /srv/www/htdocs/hle/bugzilla werden weitere Einstellungen vorgenommen, welche so in der Installationsanleitung für Bugzilla beschrieben sind. Da dieses Verzeichnis ein Unterverzeichnis zu /srv/www/htdocs/hle ist, gelten natürlich zusätzlich die oben beschriebenen IP-Zugangsbeschränkungen.
Auch das Verzeichnis /etc/apache2/vhosts.d/vhosts.conf sieht nun anders aus. Der Einfachheit halber habe ich in dieser Datei keine bedingten Schleifen untergebracht, wie es sie in /etc/apache2/vhosts.d/vhost-ssl.template gibt. Stattdessen werden direkt namensbasierte virtuelle Hosts für unverschlüsselte und für verschlüsselte Verbindungen definiert. Das sieht dann so aus:
#
# Konfiguration virtueller Hosts auf CAIPIROSKA
#
# Gabriel Rüeck, 20.10.2010
NameVirtualHost *:80
NameVirtualHost *:443
# Non-SSL-Konfiguration
<VirtualHost *:80>
ServerName caipiroska.homelinux.org
ServerAlias caipiroska
ServerAdmin gabriel@rueeck.de
DocumentRoot /srv/www/htdocs/caipiroska
ErrorLog /var/log/apache2/caipiroska_error_log
CustomLog /var/log/apache2/caipiroska_access_log combined
# Umleitungen auf die neu angemietete Domain rueeck.name
Redirect permanent /coppermine http://rueeck.name/coppermine
Redirect permanent /mediawiki http://rueeck.name/mediawiki
Redirect permanent /lx-erp https://rueeck.name/lx-erp
Redirect permanent /phpPgAdmin https://rueeck.name/phpPgAdmin
Redirect permanent /groupoffice https://rueeck.name/groupoffice
</VirtualHost>
<VirtualHost *:80>
ServerName hle.homelinux.org
ServerAdmin gabriel@rueeck.de
DocumentRoot /srv/www/htdocs/hle
ErrorLog /var/log/apache2/hle_error_log
CustomLog /var/log/apache2/hle_access_log combined
# Spezifische Alias-Definitionen
Alias /DIS /home/shared
Alias /MIS /home/shared/programs
Alias /HAL /home/shared/mediawiki
Alias /coppermine /home/shared/coppermine
Alias /pictures /home/shared/pictures
<Location /pictures>
Options Indexes
IndexOptions +IgnoreCase +FoldersFirst +VersionSort +Charset=UTF-8
</Location>
</VirtualHost>
<VirtualHost *:80>
ServerName ba-berlin.homelinux.org
ServerAdmin gabriel@rueeck.de
DocumentRoot /srv/www/htdocs/ba-berlin
ErrorLog /var/log/apache2/ba-berlin_error_log
CustomLog /var/log/apache2/ba-berlin_access_log combined
</VirtualHost>
# SSL-Konfiguration
<VirtualHost *:443>
SSLEngine on
SSLCertificateFile /etc/apache2/ssl.crt/server.crt
SSLCertificateKeyFile /etc/apache2/ssl.key/server.key
SSLOptions StrictRequire
ServerName caipiroska.homelinux.org
ServerAlias caipiroska
ServerAdmin gabriel@rueeck.de
DocumentRoot /srv/www/htdocs/caipiroska
ErrorLog /var/log/apache2/caipiroska_error_log
CustomLog /var/log/apache2/caipiroska_access_log combined
# Umleitungen auf die neu angemietete Domain rueeck.name
Redirect permanent /coppermine http://rueeck.name/coppermine
Redirect permanent /mediawiki http://rueeck.name/mediawiki
Redirect permanent /lx-erp https://rueeck.name/lx-erp
Redirect permanent /phpPgAdmin https://rueeck.name/phpPgAdmin
Redirect permanent /groupoffice https://rueeck.name/groupoffice
<Directory /srv/www/htdocs/caipiroska/MM>
AuthName "Secure Access on CAIPIRINHA"
AuthType Digest
AuthUserFile /srv/www/htdocs/caipiroska/MM/.htpasswd
Require valid-user
Options Indexes FollowSymLinks
IndexOptions +IgnoreCase +FoldersFirst +VersionSort +Charset=UTF-8
</Directory>
</VirtualHost>
<VirtualHost *:443>
SSLEngine on
SSLCertificateFile /etc/apache2/ssl.crt/hle_auf_caipiroska.crt
SSLCertificateKeyFile /etc/apache2/ssl.key/hle_auf_caipiroska.key
SSLOptions StrictRequire
ServerName hle.homelinux.org
ServerAdmin gabriel@rueeck.de
DocumentRoot /srv/www/htdocs/hle
ErrorLog /var/log/apache2/hle_error_log
CustomLog /var/log/apache2/hle_access_log combined
# Spezifische Alias-Definitionen
Alias /DIS /home/shared
Alias /MIS /home/shared/programs
Alias /HAL /home/shared/mediawiki
Alias /coppermine /home/shared/coppermine
Alias /pictures /home/shared/pictures
<Location /pictures>
Options Indexes
IndexOptions +IgnoreCase +FoldersFirst +VersionSort +Charset=UTF-8
</Location>
</VirtualHost>
<VirtualHost *:443>
SSLEngine on
SSLCertificateFile /etc/apache2/ssl.crt/ba-berlin.crt
SSLCertificateKeyFile /etc/apache2/ssl.key/ba-berlin.key
SSLOptions StrictRequire
ServerName ba-berlin.homelinux.org
ServerAdmin gabriel@rueeck.de
DocumentRoot /srv/www/htdocs/ba-berlin
ErrorLog /var/log/apache2/ba-berlin_error_log
CustomLog /var/log/apache2/ba-berlin_access_log combined
</VirtualHost>
Hier muss noch Einiges erklärt werden:
- Zunächst einmal muss man beachten, dass es insgesamt drei DocumentRoots gibt, welche den einzelnen Domains zugeordnet sind. Die Domains werden mit dem Schlüsselwort ServerName zugeordnet.
- Jede Domain hat ihre eigenen Log-Dateien. Das ist erforderlich, weil ja mit dem Paket Webalizer auch Statistiken für jede Domain getrennt erfasst werden sollen.
- Für jede Domain existiert sowohl ein Server für unverschlüsselte Verbindungen auf Port 80 als auch ein Server für verschlüsselte Verbindungen auf Port 443.
- Jeder Server für verschlüsselte Verbindungen hat sein eigenes Server-Zertifikat (*.crt) und seine eigene Schlüsseldatei (*.key), die mit den Direktiven SSLCertificateFile und SSLCertificateKeyFile zugeordnet werden.
- Speziell für die Domain caipiroska.homelinux.org gilt:
- Einige Unterseiten werden umgeleitet auf entsprechende Seiten auf der Maschine http://rueeck.name. Dies wird durch die Direktive Redirect erreicht. Die Option Permanent signalisiert dem aufrufenden Client mit dem Statuscode 301, dass der Inhalt der Webseite “endgültig” zur neuen Adresse umgezogen ist.
- Über eine gesicherte Verbindung kann man das Verzeichnis /srv/www/htdocs/caipiroska/MM erreichen, welches noch eine Authentifizierung erfordert.
- Speziell für die Domain hle.homelinux.org gilt:
- Mit der Alias-Direktive werden einige Verzeichnisse außerhalb des DocumentRoot definiert.
- Der Inhalt des Verzeichnisses /home/shared/pictures kann aufgelistet werden. Dabei werden bestimmte Sortierkriterien eingehalten, die zusätzlich (deswegen das “+”-Zeichen) zu den Default-Optionen aktiviert werden (+IgnoreCase +FoldersFirst +VersionSort). Außerdem wird das Listing mit dem Zeichensatz UTF-8 durchgeführt (+Charset=UTF-8).
Die Server-Zertifikate sind mit den Skripten des OpenVPN-Paketes erzeugt worden. Mit YaST2 müssen jetzt mit dem Editor für /etc/sysconfig noch einige Variablen beim Caipiroska-Server richtig gesetzt werden:
- Applications→SuSEhelp→DOC_HOST wird auf caipiroska.homelinux.org gesetzt.
- Applications→SuSEhelp→DOC_ALLOW bleibt leer.
- Applications→SuSEhelp→DOC_AUTOINDEX wird auf yes gesetzt.
- Network→WWW→Apache→SuSEhelp→DOC_SERVER wird auf yes gesetzt.
- Network→WWW→Apache2→APACHE_CONF_INCLUDE_FILES wird auf /etc/apache2/httpd.conf.local gesetzt, damit unsere Konfigurationsdatei von oben überhaupt verarbeitet wird.
- Network→WWW→Apache2→APACHE_CONF_INCLUDE_DIRS bleibt leer.
- Network→WWW→Apache2→APACHE_MODULES muss mindestens die Module actions alias auth_basic auth_digest authn_file authz_host authz_default authz_user autoindex cgi charset_lite dav dav_fs dav_lock deflate dir env expires imagemap include log_config mime mime_magic negotiation setenvif suexec ssl userdir php5 beinhalten.
- Network→WWW→Apache2→APACHE_SERVER_FLAGS wird auf -D SSL gesetzt, um SSL zu aktivieren.
- Network→WWW→Apache2→APACHE_HTTPD_CONF bleibt leer.
- Network→WWW→Apache2→APACHE_MPM bleibt leer.
- Network→WWW→Apache2→APACHE_SERVERADMIN wird auf root@caipiroska.homelinux.org eingestellt.
- Network→WWW→Apache2→APACHE_SERVERNAME wird auf caipiroska.homelinux.org eingestellt.
- Network→WWW→Apache2→APACHE_START_TIMEOUT wird auf 20 gestellt.
- Network→WWW→Apache2→APACHE_SERVERSIGNATURE wird auf on gesetzt.
- Network→WWW→Apache2→APACHE_LOGLEVEL wird auf warn gesetzt.
- Network→WWW→Apache2→APACHE_ACCESS_LOG wird auf /var/log/apache2/access_log combined gesetzt.
- Network→WWW→Apache2→APACHE_USE_CANONICAL_NAMES wird auf off gesetzt.
- Network→WWW→Apache2→APACHE_SERVERTOKENS wird auf OS gesetzt.
- Network→WWW→Apache2→APACHE_EXTENDED_STATUS wird auf off gesetzt.
Die hier genannten Einstellungen finden sich dann auch in den System-Dateien:
- /etc/sysconfig/susehelp
- /etc/sysconfig/apache2
Danach kann der Apache-Webserver mit /etc/init.d/apache start in Betrieb genommen werden, und alles sollte funktionieren.
Webalizer

Mit dem Paket webalizer ist es möglich, umfassende Server-Statistiken anhand der Analyse der Log-Dateien des Apache-Webservers zu erstellen. Die notwendigen Einstellungen werden in der Konfigurationsdatei /etc/webalizer.conf vorgenommen, in der sich schon sinnvolle Voreinstellungen befinden. Im Wesentlichen müssen hier folgende Einstellungen, deren Optionen ausführlich in /etc/webalizer.conf beschrieben sind, angepasst werden:
/etc/webalizer.conf:
... LogFile /var/log/apache2/access_log OutputDir /srv/www/htdocs/webalizer Incremental yes HostName caipirinha.homelinux.org UseHTTPS yes Quiet yes GMTTime yes CountryGraph no ...
Die im Bild Webserver-Statistik aufgelisteten Monate können noch weiter aufgeschlüsselt werden. So kann man sich anschauen, welche Datei am Häufigsten herunter geladen wurde, wie oft ein bestimmter Fehler, beispielsweise 404, aufgetreten ist, aus welchen Top Level Domains die Zugriffe kamen, etc.
Um die Statistiken aktuell zu halten, muss webalizer allerdings auch regelmäßig aufgerufen werden. Am Besten ist es daher, einen entsprechenden Eintrag in der crontab von root zu machen, etwa so:
... # Crontab für root # LANG = de_DE.UTF-8 LC_ALL = de_DE.UTF-8 MAILTO = root@rueeck.name SHELL = /bin/bash # 05 00 * * * umask 0022; webalizer -c /etc/webalizer.conf ...
Das hier vor den webalizer-Aufruf gestellte umask-Kommando macht die durch den Benutzer root erstellten Statistiken für alle (und damit auch für den Apache-Benutzer wwwrun) lesbar. Dies wurde erforderlich, weil auf dem Caipirinha– und auf dem Caipiroska-Server die Benutzerrechte aus Sicherheitsgründen einheitlich restriktiv auf 0077 gesetzt wurden. Damit werden dann täglich die Statistiken erneuert.
Bei einem virtuellen Server sind darüber hinaus weitere Dinge zu beachten [22]. So muss für jede virtuelle Domain jeweils eine separate webalizer-Instanz aufgerufen werden.
Samba
Samba-Server
Die Konfiguration des Samba-Dienstes auf dem Caipirinha-Server dient ausschließlich dazu, einige zentrale Verzeichnisse auf dem Server unter Windows verfügbar zu machen. Insofern stellt die unten stehende Konfigurationsdatei kein Meisterstück dar, sondern kann lediglich einige einführende Ideen geben. Sicherlich könnte man auch in einem Heim-Netzwerk noch viel bessere Konfigurationen anbieten. Aber schauen wir uns zunächst einmal die Konfigurationsdatei an:
/etc/samba/smb.conf:
# Samba Configuration File # Manually created by Gabriel Rüeck # Date: 01-JUN-2010 [global] # Die folgende Einstellung ist erforderlich für Josélias Computer mit Windows Vista. client ntlmv2 auth = yes create mask = 0640 deadtime = 60 directory mask = 0750 display charset = UTF8 domain master = no fstype = Samba guest account = nobody hosts allow = 192.168.3. 127.0.0.1 load printers = no log file = /var/log/samba/log.%m-%I log level = 1 map to guest = Bad User name resolve order = lmhosts hosts bcast netbios name = CAIPIRINHA passdb backend = smbpasswd:/etc/samba/smbpasswd printcap name = cups printing = cups server string = Caipirinha Fileserver socket options = SO_KEEPALIVE IPTOS_LOWDELAY TCP_NODELAY syslog = 0 time server = yes unix extensions = no unix charset = UTF8 username map = /etc/samba/smbusers workgroup = SPQR [homes] browseable = no comment = Home Directories create mask = 0600 directory mask = 0700 guest ok = no hide dot files = yes hide special files = yes path = %H read only = no valid users = %S veto files = /Picasa.ini/Thumbs.db/ wide links = yes [www] browseable = no comment = User Web Pages create mask = 0644 directory mask = 0755 guest ok = no hide special files = yes path = %H/public_html read only = no [ftp] comment = Verzeichnisse des FTP-Servers create mask = 0644 directory mask = 0755 force create mode = 0644 force directory mode = 0755 force group = +users hide special files = yes path = /home/ftp write list = +users [public] comment = Daten für alle Benutzer guest ok = yes hide special files = yes path = /home/public veto files = /Picasa.ini/Thumbs.db/ write list = +relationship [tmp] comment = Verzeichnis für alles Mögliche create mask = 0644 directory mask = 0755 force group = +users hide special files = yes path = /home/tmp write list = +users [backup] comment = Verschlüsseltes Backup-Laufwerk create mask = 0600 directory mask = 0700 force group = +users hide special files = yes path = /backup valid users = +users write list = +users
Alle hier benutzten Schlüsselwörter sind sehr übersichtlich in der Samba-Dokumentation [1] erläutert, die man sich auch mit man samba aufrufen kann. Einige Einstellungen werden im Folgenden näher erklärt:
- Die Einstellung für client ntlmv2 auth ist für die korrekte Authentifizierung von Windows Clients mit Windows Vista oder höher erforderlich, weil diese dafür standardmäßig NTLM benutzen.
- Die Einstellungen für create mask und directory mask in den globalen Einstellungen [global] legen zunächst fest, dass erzeugte Dateien für alle Benutzer der gleichen Gruppe lesbar und erzeugte Verzeichnisse für alle Benutzer der gleichen Gruppe zugänglich sein sollen. Es handelt sich also dabei um die umask erzeugter Dateien und Verzeichnisse.
- Mit display charset wird UTF8 als Zeichensatz eingestellt, so wie er auch auf dem Projektmanagement-Server selbst benutzt wird. Dann gibt es keine Probleme bei der Darstellung akzentuierter Zeichen oder von Dateinamen, welche nicht in lateinischen Buchstaben geschrieben sind.
- Mit den angegebenen Adreßbereichen unter hosts allow begrenzt man die zugriffsberechtigten Clients auf das Netzwerk 192.168.3.0/24 und den localhost (127.0.0.1). Der Eintrag des localhost ist besonders wichtig, weil beim Fehlen desselben der Befehl
smbpasswdauf dem Server nicht mehr funktioniert. - passdb backend legt fest, dass bei dieser Konfiguration noch die alte Methode zur Speicherung der Zugangsdaten (nämlich die Datei /etc/samba/smbpasswd) eingesetzt wird. Der Einsatz dieser Methode ist aber nicht mehr empfohlen.
- Mit der hier gezeigten Einstellung für time server bietet sich der Caipirinha-Server den sich mit ihm verbindenden Windows-Clients als Zeitreferenz an. Dies ist eine gute Idee, denn durch die ntp-Konfiguration hat der Caipirinha-Server ja eine gut abgeglichene Uhrzeit.
- Den Namen der Arbeitsgruppe stellt man mit workgroup ein; er sollte auf denselben Namen lauten, den auch die anderen (Windows-) Maschinen als Arbeitsgruppe eingestellt haben. Der Server macht sich mit dem unter nebios name eingestellten Namen im Netzwerk bekannt. Hier nimmt man am Besten den Maschinennamen, damit die Fehlersuche und die Administration einfacher werden.
- Unter username map ist eine Datei referenziert, welche eine Zuordnung von Benutzernamen der Clients zu Benutzernamen auf dem Samba-Server auflistet.
Danach folgen in der Konfigurationsdatei verschiedene Abschnitte, welche jeweils ein bestimmtes unter path genanntes Verzeichnis “exportieren”. Hier handelt es sich um die Abschnitte:
- [homes] exportiert %H; in Windows Q:
- [www] exportiert %H/public_html; in Windows W:
- [ftp] exportiert /home/ftp; in Windows V:
- [public] exportiert /home/public; in Windows S:
- [tmp] exportiert /home/tmp; in Windows T:
- [backup] exportiert /backup; in Windows U:
Hier sind noch einige Anmerkungen zu den einzelnen Abschnitten:
- Die Angabe %H im Pfadnamen in den Abschnitten [homes] und [www] wird durch das Home-Verzeichnis des jeweiligen Benutzers ersetzt [2], also beispielsweise durch /home/gabriel, wenn sich der Benutzer gabriel mit dem Samba-Dienst verbindet (und auch verbinden darf).
- Für das Verzeichnis %H im Abschnitt [homes] werden mit 0600 und 0700 sehr restriktive Dateirechte vergeben, denn es handelt sich ja um das persönliche Verzeichnis eines Benutzers.
- Für das Verzeichnis %H/public_html im Abschnitt [www] werden dagegen mit 0644 und 0755 sehr offene Dateirechte vergeben, denn es handelt sich ja um das Verzeichnis für die persönliche Homepage des entsprechenden Benutzers, und die soll ja auch für andere Benutzer (in diesem Fall für den Benutzer wwwrun, mit dem der Apache-Dienst läuft) sichtbar sein. Man muss beachten, dass das Verzeichnis %H/public_html (Abschnitt [www]) auch über %H (Abschnitt [homes]), also über das persönliche Verzeichnis, erreicht werden kann. Die Dateirechte hängen aber davon ab, über welchen Samba-Share man sich verbindet. Man schreibt daher seine Webseiten am Besten immer nur über den Samba-Share [www], denn nur dann können die Webseiten auch von allen Benutzern (und damit auch vom Benutzer wwwrun, mit dem der Apache-Dienst läuft) gelesen werden. Eigentlich hätte ich auch noch erwartet, dass man hier explizit die Einstellungen force create mode und force directory mode konfigurieren muss, so wie dies im Share [ftp] gemacht wurde. Auf dem Caipirinha-Server ist nämlich die umask für die Benutzer auf restriktive 0077 gesetzt. Aus einem mir unerfindlichen Grund muss man das aber nicht machen; vielleicht ein Bug in der aktuell eingesetzten Samba-Version 3.4.3 in Verbindung mit openSuSE?
- Die Einstellung für wide links im Samba-Share [homes] erlaubt das Verlinken von Dateien aus dem Bereich von %H heraus. Dies wurde hier erforderlich, die Benutzerverzeichnisse durch das Skript Doppelte Dateien löschen durchforstet werden, welches dann möglicherweise auch Links aus den Benutzerverzeichnissen heraus nach /home/public erstellt. Sonst könnte auf diese verlinkten Dateien direkt auf dem Caipirinha-Server zugreifen, nicht aber über Samba. wide links sollte aber immer mit Vorsicht eingesetzt werden, denn es eröffnet natürlich auch Zugriffsmöglichkeiten auf Verzeichnisse, die man sonst vielleicht gar nicht über Samba zugänglich machen wollte.
- Beim Verzeichnis /home/ftp (Abschnitt [ftp]) werden weitergehende Dateirechte festgelegt bzw. erzwungen, damit Benutzer Dateien aus den Verzeichnissen /home/ftp/upload und /home/ftp/download bearbeiten können und diese dann auch vom FTP-Dienst gelesen werden können.
- In das Verzeichnis /home/public (Abschnitt [public]) dürfen nur Benutzer schreiben, welche der Gruppe relationship angehören. So ist es in write list definiert worden.
- In das Verzeichnis /home/tmp (Abschnitt [tmp]) dürfen dagegen alle Benutzer schreiben, die zur Gruppe users gehören.
- Für das Verzeichnis /backup im Abschnitt [backup] sind ebenfalls sehr restriktive Dateirechte vergeben worden. Es soll ja niemand die Backups eines anderen Benutzers lesen können. Darüber hinaus dürfen nur Mitglieder der Gruppe users über Samba auf dieses Verzeichnis zugreifen (valid users). Es dürfen auch nur Mitglieder der Gruppe users über Samba auf dieses Verzeichnis schreiben (write list).
In der Datei /etc/samba/smbusers sind, wie bereits erwähnt wurde, die Benutzernamen der Clients in Benutzernamen auf dem Samba-Server übersetzt:
... #root = administrator #nobody = guest pcguest smbguest gabriel = "Gabriel Rüeck" Gabriel joselia = "Josélia da Silva" Josélia
Wie man sieht, gibt es nur zwei Benutzer, nämlich gabriel und joselia, die sich als Gabriel und Josélia auf den Windows-Clients anmelden.

Einbinden eines Netzlaufwerks auf einem Windows-Client
Das Passwörter für die Samba-Benutzer gabriel uns joselia sind in der Datei /etc/samba/smbpasswd
enthalten, allerdings in verschlüsselter Form. Es wurde hier das
gleiche Passwort gewählt wie beim Login auf den Windows-Clients, so dass
die Netzlaufwerke einfach unter Windows gemountet werden können. Es ist
wichtig zu wissen, dass das Samba-Passwort eines Benutzers vom
Systempasswort des Benutzers abweichen kann. Das Samba-Passwort kann in
einer Linux-Shell mit dem Befehl smbpasswd gesetzt werden.
Windows-Client
Unter den verschiedenen Windows-Versionen funktioniert die Einbindung der durch Samba “exportierten” Netzlaufwerke immer nach der gleichen einfachen Art und Weise. Im Windows Explorer wählt man den Menüpunkt Extras und dann Netzlaufwerk verbinden. Danach sucht man einen Laufwerksbuchstaben aus und gibt bei Ordner den vollständigen Pfad zum freigegebenen Verzeichnis ein, so wie rechts abgebildet. Außerdem markiert man noch die Option Verbindung bei Anmeldung wiederherstellen, so dass das Netzlaufwerk permanent eingebunden wird. Im Beispiel rechts wurde die Maschine mit dem unter netbios name angegebenen Namen (caipirinha) eingebunden. Dies funktioniert meist nur im lokalen Netzwerk (bzw. generell in den Netzwerken, in welche die smb- und nmb-Pakete weitergeleitet werden). Weitere Möglichkeiten sind die Angabe der IP-Adresse oder der volle Maschinenname (FQDN).
Drucken über Samba
Lange Zeit hatte ich über Samba auch Zugriffsmöglichkeiten auf die am Caipirinha-Server installierten Drucker angeboten. Allerdings gab dies, insbesondere mit Windows-Clients, die sich als Gast anmeldeten, immer wieder Probleme, und so habe ich mich entschlossen, Druck- und Dateidienste komplett zu trennen und die Druckdienste ausschließlich über CUPS anzubieten.
Caipithek
Die Caipithek ist eine private Online-Videothek auf dem Caipirinha-Server. Sie basiert im Wesentlichen auf dem VLC Media Player, einem Shell-Skript und einem PHP-Skript.
Benutzung
Zur Benutzung der Caipithek sollte auf dem Client-Computer der VLC Media Player installiert sein. Mit diesem gelungenen Programm, welches für verschiedene Plattformen erhältlich ist, können nämlich sehr viele Video- und Audioformate wiedergegeben werden.
Nach dem Aufrufen der durch eine Anmeldung geschützte Startseite der Caipithek bekommt der Benutzer ein Auswahlfenster mit der zur Verfügung stehenden Videos angezeigt. Die maximale Anzahl der Videos, welche zur Wiedergabe ausgewählt werden können, ist über diesem Auswahlfenster angegeben.
Der Benutzer wählt nun einen oder mehrere Video aus und konfiguriert die unter dem Auswahlfenster aufgelisteten Wiedergabe-Optionen. Darunter fallen:
- Video-Codec: Hier ist H.264 vorselektiert, weil bei diesem Format die beste Qualität erreicht wird.
- Bandwidth: Hier wird die Bandbreite für den Stream eingestellt. Eine höhere Bandbreite bietet eine bessere Wiedergabe-Qualität, erhöht aber auch die Wahrscheinlichkeit von Aussetzern, wenn der Übertragungskanal beschränkt ist.
- Audio Stream: Die meisten Videos haben mehrere Tonspuren. Wählt man hier 1, hat man meist den deutschen Ton, die Auswahl von 2 liefert meist den englischen Ton. Haben nicht alle ausgewählten Videos mehrere Tonspuren, so wird bei der Wiedergabe immer Tonspur 1 benutzt.
Nach Betätigen des Start-Knopfes erscheint eine neue Seite mit
Angaben zu den ausgewählten Videos und zu den Wiedergabe-Optionen. Die
Wiedergabe der Videos sollte nach wenigen Sekunden starten. Das
Wiedergabefenster kann auch auf ein Vollbild aufgezogen werden.
Will man die Wiedergabe abbrechen, muss beachtet werden, dass man nicht einfach das Browserfenster schließen darf, sondern dass man wirklich auf den Exit-Knopf drückt, damit das Streaming des Videos auch im Server korrekt abgebrochen wird.
Man kommt dann nach einigen Sekunden wieder auf die Startseite der Caipithek zurück.
Installation
Die Caipithek basiert auf dem erfolgreichen Zusammenspiel dieser Komponenten:
- einem im Hintergrund laufenden VLC-Serverprozeß
- einem Shell-Skript, das eine Liste aller Videos erzeugt
- einer Konfigurationsdatei für das PHP-Skript
- einem PHP-Skript, welches über den Apache-Server die Schnittstelle zum Benutzer darstellt
Zunächst müssen aber folgende Pakete auf dem Server installiert werden:
- gnome-vfs2
- grep
- mediainfo (ab Version 0.7.26)
- sed
- vlc
- vlc-noX
Eventuell werden dadurch noch weitere Pakete automatisch installiert. Weiterhin müssen ein funktionierender Webserver, beispielsweise Apache, und eine korrekte PHP-Installation vorhanden sein.
Icons
Das PHP-Skript benutzt Buttons zur Visualisierung von Funktionen. Unter /usr/share/icons/gnome/32×32/actions habe ich einige schöne Buttons gefunden, welche nun zunächst über den Apache-Server “sichtbar” gemacht werden sollen. Dazu werden folgende Einträge in der Datei /etc/apache2/httpd.conf.local vorgenommen:
Alias /gnome-icons /usr/share/icons/gnome/32x32
<Directory /usr/share/icons/gnome/32x32>
Order allow,deny
Allow from all
</Directory>
Danach muss die geänderte Konfiguration noch mit /etc/init.d/apache2 reload oder mit /etc/init.d/apache2 restart aktiviert werden.
VLC-Serverprozeß
Dann wird der VLC-Serverprozeß mit einem telnet-Interface im Hintergrund gestartet. Ich verwende dazu den gleichen Benutzer (wwwrun) wie für den Apache-Webserver. Für diesen Benutzer muss dann aber auch eine Login-Shell existieren; man also beispielsweise für wwwrun in der Benutzer-Verwaltung /bin/bash anstatt /bin/false einstellen. Dementsprechend sollte man auch ein sicheres Passwort wählen. Die entsprechenden Befehle sehen bei mir in einer root-Konsole also so aus:
caipirinha:~ # su -l wwwrun wwwrun@caipirinha:~> cvlc -I oldtelnet --telnet-password geheimes_passwort > cvlc.log 2>&1 & [1] 21639 wwwrun@caipirinha:~> exit logout caipirinha:~ #
geheimes_passwort muss natürlich durch ein selbstgewähltes Passwort ersetzt werden. Wichtig ist die Option oldtelnet, welche seit VLC 1.1.0 benutzt werden muss (davor war es nur telnet). Damit wurde nun VLC im Hintergrund gestartet, und auf Port 4212 kann man sich nun mit dem VLC-Server über telnet verbinden. Der VLC-Serverprozeß ist der Kern der Videothek. Über diesen Prozeß wird der Video-Stream erzeugt und bei Bedarf auch transkodiert (also große Videos auf eine kleine Bitrate “herunter gerechnet”).
Shell-Skript
Das nächste wichtige Element ist ein Shell-Skript (filmliste.sh), welches über cron
regelmäßig aufgerufen wird, in meinem Fall immer montags. Dieses
Shell-Skript erstellt eine Liste aller Videos mit einigen
Zusatzinformationen. Dazu durchsucht es mit dem Befehl gnomevfs-info das Verzeichnis VIDEODIR nach Videos, extrahiert mit dem Programm mediainfo, und zwar ab Version 0.7.26.
Einzelheiten über as Format, die Anzahl der Video-Streams, die Anzahl
der Audio-Streams und die Länge des Videos und schreibt dann für jede
gefundene Video eine Zeile in die Datei VIDEOLIST.
filmliste.sh:
#!/bin/bash
#
# This script searches for video files in the specified folder and creates an ordered list of the files.
#
# Gabriel Rüeck, gabriel@caipirinha.homelinux.org, 18.01.2010
#
# Pre-define some variables and read the configuration files.
readonly VIDEODIR='/home/public/Video'
readonly VIDEOLIST='/home/public/Video/Filmliste.txt'
# Delete the old file
rm "$VIDEOLIST"
# Scan the specified directory for a sorted list of files that can be read by "others".
cd "$VIDEODIR" && find . -perm -004 -type f -print 2>/dev/null | sort |
# The following commands will be executed in a subshell; they would anyway because they follow the pipe (|) symbol.
# But first the variable IFS is set to "|" as separator. Normally, IFS is set to " ". This is important for the read command as IFS
# contains the character that is used as a separator for the read command. A " " as separator leads to problems when the file name has
# a double white space like " " or so in the name as read would report this back as a single white space " ". That !$#% cost me a day...
(OLD_IFS=$IFS
IFS=""
while read -r FILE_NAME;
# Use gnomevfs-info as it determines videos with a higher reliability than the file command. Test if the MIME type starts with "video/".
# If that is the case, store the MIME type in $VIDEO_TYPE, otherwise set $VIDEO_TYPE to "".
do VIDEO_TYPE=$(gnomevfs-info $FILE_NAME | sed -n 's/\(^MIME type *:\) \(.*\)/\2/p' | fgrep 'video/')
if [ $VIDEO_TYPE ]; then
# If a video stream has been identified, store the result in the output file. Use ":" as separator.
DATA=$(mediainfo -f "$FILE_NAME")
WIDTH=$(echo $DATA | sed -n 's/^Width[^:]*:[^0-9]*\([0-9].*\)/\1/p' | head -n1)
HEIGHT=$(echo $DATA | sed -n 's/^Height[^:]*:[^0-9]*\([0-9].*\)/\1/p' | head -n1)
DURATION=$[$(echo $DATA | sed -n 's/^Duration[^:]*:[^0-9]*\([0-9].*\)/\1/p' | head -n1)/1000]
VIDEO_STREAMS=$(echo $DATA | sed -n 's/^Count of video streams[^:]*:[^0-9]*\([0-9].*\)/\1/p' | head -n1)
AUDIO_STREAMS=$(echo $DATA | sed -n 's/^Count of audio streams[^:]*:[^0-9]*\([0-9].*\)/\1/p' | head -n1)
echo -e "${FILE_NAME:2}:$WIDTH:$HEIGHT:$VIDEO_STREAMS:$AUDIO_STREAMS:$DURATION" >> $VIDEOLIST
fi
done;
# Reset IFS to its old value
IFS=$OLD_IFS)
Das Skript läuft unter einem normalen Benutzer-Account und sucht sowieso nur nach Dateien, die für others lesbar sind. Die resultierende Text-Datei hat dann beispielsweise Einträge wie diese:
_BRASILIEN/Cidade dos Homens/Folge 1.avi:672:512:1:2:2121 _BRASILIEN/Cidade dos Homens/Folge 2.avi:672:496:1:2:1646 _BRASILIEN/Cidade dos Homens/Folge 3.avi:672:464:1:2:1781 _BRASILIEN/Cidade dos Homens/Folge 4.avi:672:496:1:2:1895
Alle Einträge einer Zeile sind durch einen Doppelpunkt getrennt. Für jedes Video werden folgende Informationen erfasst:
- Pfad und Name des Videos, relativ zu VIDEODIR
- Breite des Videos in Pixeln
- Höhe des Videos in Pixeln
- Anzahl der Video-Streams
- Anzahl der Audio-Streams
- Länge des Videos in Sekunden
Damit dieses Skript erfolgreich funktioniert, dürfen allerdings weder im Pfadnamen noch im Dateinamen Doppelpunkte vorkommen.
Konfigurationsdatei
Das PHP-Skript der Caipithek selbst benötigt noch eine Konfigurationsdatei namens .caipithek, welche sich im gleichen Verzeichnis wie caipithek.php befinden muss. Hier ist ein Beispiel einer funktionierenden Konfigurationsdatei:
.caipithek
;;;;;;;;;;;;;; ; File Paths ; ;;;;;;;;;;;;;; movie_list = /home/public/Video/Filmliste.txt movie_path = /home/public/Video/ log_file = /var/lib/wwwrun/caipithek.log ;;;;;;;;;;;;;;;;;;;; ; System Variables ; ;;;;;;;;;;;;;;;;;;;; max_streams = 1 max_inputs = 2 max_width = 1024 max_height = 576 vlc_host = localhost vlc_port = 4212 vlc_pwd = geheimes_passwort vlc_stream = 192.168.2.2:8008 public_add = caipirinha.homelinux.org:8008
Die meisten Einträge in der Konfigurationsdatei sind selbsterklärend. geheimes_passwort ist das gleiche selbstgewählte Passwort, welches schon beim Starten des VLC-Serverprozesses angegeben worden ist. max_streams legt die Anzahl der gleichzeitig transkodierten Streams fest. Auf dem Caipirinha-Server wären hier alleine von der Rechenleistung her maximal 2 gleichzeitige Streams möglich, aber bei der geringen Upload-Rate meines ADSL-Anschlusses habe ich max_streams auf 1 gesetzt. max_inputs legt die maximale Anzahl der Videos fest, welche zur direkt aufeinander folgenden Wiedergabe ausgewählt werden können. max_width und max_height definieren die maximale Größe, die beim Streamen über das Internet möglich ist. Damit werden Videos in HD-Auflösung herunter skaliert, weil die volle HD-Auflösung beim geringen Upload der ADSL-Verbindung zu ruckelnden Bildern führen würde. Beim reinen Streamen eines Videos (ohne Transkodierung), was nur im LAN möglich ist, können auch Videos in HD-Auflösung wiedergegeben werden. vlc_stream legt die Adresse und den Port fest, an dem der VLC-Serverprozeß den Stream anbieten wird. Die IP-Adresse muss natürlich die IP-Adresse der Maschine sein, auf der der VLC-Serverprozeß selbst läuft. Mit public_add definiert man die IP-Adresse und den Port, wie man auf den Stream vom Internet aus zugreift. Deshalb ist hier auch der FQDN (caipirinha.homelinux.org) angegeben. Der Port ist in meiner Konfiguration der gleiche wie in der Variable vlc_stream, weil ich den entsprechenden Port auf dem ADSL-Router direkt zum Caipirinha-Server durchreiche. log_file legt schließlich fest, wohin die Log-Datei geschrieben werden soll. Fehlt dieser Eintrag, so werden vom PHP-Skript dennoch Log-Einträge erzeugt, aber nach /dev/null geschrieben.
PHP-Skript
Das PHP-Skript stellt die Schnittstelle der Caipithek zum Benutzer dar. Es liest die vom Shell-Skript erzeugte Filmliste und die Konfigurationsdatei ein. Das Skript arbeitet mit Session Cookies und kann 3 verschiedene Stati annehmen:
- Status 1: Die Einstiegsseite wird angezeigt, Videos werden in einem Auswahlfenster angezeigt und Optionen zum Transkodieren oder (im LAN) zum reinen Streaming werden angeboten.
- Status 2: Die ausgewählten Videos werden transkodiert und gestreamt (oder im LAN nur gestreamt) und im Browser-Fenster des Client-Computers mittels eines Plugin wiedergegeben.
- Status 3: Der Wiedergabekanal wird entfernt, und das PHP-Skript geht automatisch in Status 1 über.
Filmauswahl
Das PHP-Skript liest die vom Shell-Skript erzeugte Filmliste ein und bereitet die darin enthaltenen Informationen visuell auf. Darüber hinaus werden Wiedergabe-Optionen zur Auswahl angeboten:
- Video-Codec: Hier ist H.264 vorselektiert, weil bei diesem Format die beste Qualität erreicht wird.
- Bandwidth: Hier wird die Bandbreite für den Stream eingestellt. Da mein ADSL-Anschluß nur etwa 630 kbps im Uplink erlaubt, wird hier normalerweise 544 kbps als maximale Bandbreite angeboten (damit mein Uplink nicht ganz “dicht” gemacht wird).
- Audio Stream: Die meisten der Videos haben eine deutsche und eine englische Tonspur. Wählt man hier 1, hat man also meist den deutschen Ton, die Auswahl von 2 liefert dann den englischen Ton. Die hier gesetzte Auswahl wird aber nur dann berücksichtigt, wenn alle ausgewählten Videos auch mehrere Tonspuren haben. Ansonsten wird nur die Tonspur 1 wiedergegeben.
Nach Betätigen des Start-Knopfen wechselt das Skript in den Status 2 zur Wiedergabe der ausgewählten Videos.
Wiedergabe
In Abhängigkeit der gewählten Videos und Optionen werden jetzt Werte festgelegt für:
- den MIME-Typ des zu übertragenden Streams (
$mimetype) - den Transport-Multiplexer (
$mux) - die Video-Bitrate (
$vb) - die Audio-Bitrate (
$ab) - die maximale Auflösung, welche sich aus der maximalen Breite aller
Videos und der maximalen Höhe aller Videos zusammen setzt und ggf. bei
HD-Videos noch weiter beschränkt wird (
$widthund$height) - die Audio-Spur, welche übertragen wird (
$audio)
Dabei werden bereits die gewählten Filme über einen telnet-Kanal auf Port 4212 zum im Hintergrund laufenden VLC-Serverprozeß übertragen und auch in der Log-Datei vermerkt. Außerdem wird eine zufällig generierte Kanalnummer erzeugt. Diese hat den Zweck, den Zugriff auf den Video-Stream für Unbefugte möglichst zu erschweren. Sicherer wäre es natürlich, hier noch einmal eine Authentifizierung des Benutzers vorzunehmen, und VLC sieht ja auch eine entsprechende Möglichkeit vor [1]. Allerdings wirkt sich ein zusätzliches Popup-Fenster zur Eingabe eines Banutzernamens und eines Passwortes nachteilig auf das Handling der Webseite aus. Eine weitere Überlegung wäre auch gewesen, den Datenstrom zu verschlüsseln [2]. Es gibt also durchaus Spielraum, den Streaming-Vorgang noch weiter abzusichern. Hier wurde nur der zugegebenermaßen “unsichere” Weg der zufällig erzeugten Kanalnummer gewählt.
In Abhängigkeit vom gewählten Container-Format (ts oder asf) wird nun mit Active-X entweder ein VLC-Plugin oder ein Media Player-Plugin aktiviert. Den HTML-Code dazu habe ich aber selbst auch von verschiedenen Web-Seiten [3] [4] [5] [6] übernommen; er stammt nicht von mir selbst.
Bei der Caipithek habe ich mich dafür entschieden, zwei Player zu unterstützen, den VLC Media Player und den Windows Media Player. Der Windows Media Player kann allerdings meines Wissens Streams nur im ASF-Format wiedergeben und kommt außerdem in der Standard-Installations mit nur wenigen Video-Codecs daher. Deswegen und wegen der in [7] aufgelisteten Beschränkungen habe ich mich entschieden, folgende Zuordnung vorzunehmen:
- asf-Container haben WMV2 als Video-Format
- ts-Container haben H.264-, MPEG4- oder MPEG2 als Video-Format
Für Hinweise zu anderen Lösungen bin ich aber jederzeit sehr dankbar.
Wiedergabe beenden
Ein kleiner Schönheitsfehler ist, dass der Benutzer nicht einfach den Browser schließen darf, wenn er das Streaming abbrechen will, sondern dass er auf den Exit-Knopf drücken muss. Erst dann wird nämlich auch das Transkodieren und Streamen im Server unterbrochen. Schließt der Benutzer einfach das Browser-Fenster, ohne vorher auf Exit zu drücken, läuft die Transkodierung eventuell weiter und blockiert einen der durch max_streams erlaubten Kanäle, bis alle Videos abgelaufen sind. Auf jeden Fall wird beim Aufruf der Startseite der Caipithek nach Kanälen mit bereits abgelaufenen Filmen gesucht, die dann gelöscht werden. Dieser Vorgang wird dann auch in den Log-Dateien vermerkt.
caipithek.php
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html>
<head>
<title>Caipithek</title>
<style type="text/css">
a:link { text-decoration:underline; font-weight:normal; color:#0000FF; }
a:visited { text-decoration:underline; font-weight:normal; color:#800080; }
a:hover { text-decoration:underline; font-weight:normal; color:#909090; }
a:active { text-decoration:blink; font-weight:normal; color:#008080; }
h1 { font-family:Arial,Helvetica,sans-serif; font-size:small; color:maroon; text-indent:0.0cm; }
h2 { font-family:Arial,Helvetica,sans-serif; font-size:small; color:green; text-indent:0.0cm; }
h3 { font-family:Arial,Helvetica,sans-serif; font-size:small; color:black; text-indent:0.0cm; }
h4 { font-family:Arial,Helvetica,sans-serif; font-size:x-small; color:black; text-indent:0.5cm; }
h5 { font-family:Arial,Helvetica,sans-serif; font-size:x-small; color:black; text-indent:1.0cm; }
hr { text-indent:0.0cm; height:3px; width:100%; text-align:left; }
li { font-family:Courier New; font-size:x-small; color:blue; }
p { font-family:Arial,Helvetica,sans-serif; font-size:x-small; color: black; text-indent:0.0cm; }
th { font-family:Arial,Helvetica,sans-serif; font-size:x-small; color: black; text-indent:0.0cm; }
td { font-family:Courier New,sans-serif; font-size:x-small; color: black; text-indent:0.0cm; }
body { background-color:#FFFFD8; padding:0px; }
div.mybody { margin-left:100px; margin-top:20px; margin-right:20px; margin-bottom:20px; }
</style>
<link rel="shortcut icon" href="http://caipirinha.homelinux.org/favicon.ico">
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<meta http-equiv="content-language" content="de">
<meta name="author" content="root">
<meta name="date" content="2010-08-12T17:30:00+0200">
<meta name="description" lang="de" content="Caipirinha Videothek">
<meta name="robots" content="noindex">
</head>
<body>
<?php
/* FUNCTIONS */
function read_until_prompt ($fp) {
/* Read until a '>' char is found. */
do;
while (fgetc($fp) != ">");
/* Read the following space char. */
fgetc($fp);
}
function chk_stream ($fp) {
/* Read until a trimmed (bare of leading and trailing spaces) line starting with the word 'output' is found. */
do $line = trim(fgets($fp,200));
while (substr($line,0,6) != "output");
return (substr($line,9,9) == "#standard");
}
function read_until_instances ($fp) {
/* Read until a trimmed (bare of leading and trailing spaces) line with the word 'instances' is found. */
do;
while (trim(fgets($fp,200)) != "instances");
}
/* PROGRAM CODE */
/* Read the configuration file. */
$cfg_db = dba_open (".caipithek","r","inifile") or die ("Caipithek config file could not be found.");
$movie_list = dba_fetch ("movie_list",$cfg_db) or die ("The variable 'movie_list' has not been specified.");
$movie_path = dba_fetch ("movie_path",$cfg_db) or die ("The variable 'movie_path' has not been specified.");
$log_file = dba_fetch ("log_file",$cfg_db) or $log_file="/dev/null";
$max_streams = dba_fetch ("max_streams",$cfg_db) or $max_streams=2;
$max_inputs = dba_fetch ("max_inputs",$cfg_db) or $max_inputs=2;
$max_width = dba_fetch ("max_width",$cfg_db) or $max_width=960;
$max_height = dba_fetch ("max_height",$cfg_db) or $max_height=540;
$vlc_host = dba_fetch ("vlc_host",$cfg_db) or $vlc_host="localhost";
$vlc_port = dba_fetch ("vlc_port",$cfg_db) or $vlc_port=4212;
$vlc_pwd = dba_fetch ("vlc_pwd",$cfg_db) or $vlc_pwd="admin";
$vlc_stream = dba_fetch ("vlc_stream",$cfg_db) or die ("The variable 'vlc_stream' has not been specified.");
$public_add = dba_fetch ("public_add",$cfg_db) or die ("The variable 'public_add' has not been specified.");
dba_close ($cfg_db);
/* This program has different states (like a state machine:
1: This is the DEFAULT state. In this mode, the list of movies and the coding options are displayed.
2: This is the PLAY state. In this mode, the movies are being transcoded and displayed on the client browser.
The user can change to state 3 or state 4 from here.
3: This is the STOP state. The channel is deleted from the VLC server.
State 3 is automatically left for state 1 after some seconds. */
/* Determine what the page shall display. */
if (!count($_POST))
$state = 1;
else
if (isset($_POST['state'])) {
$state = $_POST['state'];
if ($state == 2)
if (isset($_POST['movies']) and isset($_POST['vcodec']) and isset($_POST['audio'])) {
$movies = $_POST['movies'];
$vcodec = $_POST['vcodec'];
$audio = (int) $_POST['audio']; /* Without the explicit (int) the variable would be read as a string. */
isset($_POST['bw']) ? $bw=$_POST['bw'] : $bw=1; /* $bw may be unset for local access when 'streaming' is pre-selected. */
} else $state = 1;
if ($state == 3)
if (isset($_POST['channel']))
$channel = $_POST['channel'];
else $state = 1;
} else
$state = 1;
/* Determine if the client is on the local network. If yes, set $is_local=true. */
$is_local = false;
unset($output);
exec('/sbin/ifconfig | sed -n \'s/.*inet [^0-9]*\([0-9]\{1,\}.[0-9]\{1,\}.[0-9]\{1,\}.[0-9]\{1,\}\).*M[^0-9]*\([0-9]\{1,\}.[0-9]\{1,\}.[0-9]\{1,\}.[0-9]\{1,\}\).*/\1.\2/p\'',$output);
foreach ($output as $ip_pair) {
/* Determine the local network. */
$local_ip = (int) strtok($ip_pair,".");
for ($counter=1; $counter<4; $counter++)
$local_ip = $local_ip<<8 | (int) strtok(".");
$netmask = (int) strtok(".");
for ($counter=1; $counter<4; $counter++)
$netmask = $netmask<<8 | (int) strtok(".");
/* Determine the remote network. */
$remote_ip = (int) strtok($_SERVER['REMOTE_ADDR'],".");
for ($counter=1; $counter<4; $counter++)
$remote_ip = $remote_ip<<8 | (int) strtok(".");
/* Check if $local_ip and $remote_ip belong to the same subnet. */
$is_local |= ($local_ip & $netmask) == ($remote_ip & $netmask);
}
/* Open log file. */
$log_ptr = fopen ($log_file,"a") or die ("The file $log_file cannot be opened.");
/* Open telnet session to VLC server process and log in with $vlc_pwd. */
if (!($vlc_ptr = fsockopen($vlc_host,$vlc_port,$errno,$errdesc,4))) {
print ("<p style=\"color:red\">An error has occured. The VLC Server cannot be contacted: ".$errno." - ".$errdesc."</p>\n");
print ("<p>The error has been logged.</p>\n");
print ("</body>\n</html>\n");
fprintf($log_ptr,"%s: The VLC Server is unavailable: %s, %s\n",date("Y-m-d H:i:s"),$errno,$errdesc);
fclose ($log_ptr);
exit (1);
}
fgets($vlc_ptr,14);
fputs($vlc_ptr,$vlc_pwd."\n");
read_until_prompt($vlc_ptr);
switch ($state) {
case 2:
print ("<h1>Caipithek - Watch Movie</h1>\n");
$width = 9999;
$height = 9999;
switch ($vcodec) {
case "h264": $mimetype="video/3gpp";
$mux="ts";
break;
case "mp4v": $mimetype="video/mp4";
$mux="ts";
break;
case "mp2v": $mimetype="video/mpeg";
$mux="ts";
break;
case "WMV2": $mimetype="video/x-ms-wmv";
$mux="asf";
break;
default: $mimetype="video/mp4";
$mux="ts"; /* Then, VLC rather than Windows Media Player will be selected for pure streaming.*/
}
switch ($bw) {
case 2: $vb = 320; /* 384 kbps in total */
$ab = 64;
break;
case 3: $vb = 384; /* 448 kbps in total */
$ab = 64;
break;
case 4: $vb = 448; /* 544 kbps in total */
$ab = 96;
break;
case 5: $vb = 1024; /* 1152 kbps in total; only offered when acces happens from local network */
$ab = 128;
break;
default: $vb = 208; /* 256 kbps in total */
$ab = 48;
}
$channel = "V".rand(100000000,999999999);
fputs($vlc_ptr,"new ".$channel." broadcast enabled\n");
read_until_prompt($vlc_ptr);
print("<p>The following movies will now be streamed:</p>\n<ul>\n");
foreach ($movies as $movie) {
if (!$max_inputs--) break;
/* Separate the movie name, the movie width and the movie height from the input. */
$movie_name = base64_decode(strtok($movie,":"));
/* Determine the smallest image size of all selected movies as this determines the resolution of the stream. */
$width = min(strtok(":"),$width);
$height = min(strtok(":"),$height);
$audio = min(strtok(":"),$audio);
fputs($vlc_ptr,"setup ".$channel." input \"".$movie_path.$movie_name."\"\n");
read_until_prompt($vlc_ptr);
print("<li>".$movie_name."</li>\n");
/* Store the movie names in the log file. */
fprintf($log_ptr,"%s, %s: Channel %s linked to movie '%s'.\n",date("Y-m-d H:i:s"),$_SERVER['REMOTE_ADDR'],$channel,$movie_name);
}
print("</ul>\n");
if (($vcodec == "stream") or (($width <= $max_width) and ($height <= $max_height))) {
print("<p>The smallest image size of all the selected movies determines the resolution of the video stream. It has been set to: <b>".$width."</b> x <b>".$height."</b> pixels.");
} else {
/* Limit width and height of the image for transcoded streams so that the movie remains fluent. */
$width = min ($width,$max_width);
$height = min ($height,$max_height);
print("<p>The resolution of the video stream has been reduced in order to cater for the limited bandwidth. It has been set to: <b>".$width."</b> x <b>".$height."</b> pixels.");
}
print(" Audio channel <b>".$audio."</b> has been selected.</p>\n");
/* Select Audio Channel. Usually, my movies are encoded with two audio streams. */
fputs($vlc_ptr,"setup ".$channel." option audio-track=".($audio-1)."\n");
read_until_prompt($vlc_ptr);
print("<p>Streaming will be done using the channel: <a href=\"http://".$public_add."/".$channel."\"><b>http://".$public_add."/".$channel."</b></a></p><hr>\n");
if ($vcodec == "stream") {
/* If pure streaming has been selected, do not transcode, but just stream the movie. */
fputs($vlc_ptr,"setup ".$channel." output #standard{access=http{mime=\"".$mimetype."\"},mux=ts,dst=".$vlc_stream."/".$channel."}\n");
/* Update the channel status in the log file. */
fprintf($log_ptr,"%s, %s: Channel %s streaming without transcoding. Audio stream %d is selected.\n",date("Y-m-d H:i:s"),$_SERVER['REMOTE_ADDR'],$channel,$audio);
} else {
/* If a bandwidth has been selected, transcode the movie. */
fputs($vlc_ptr,"setup ".$channel." output #transcode{vcodec=".$vcodec.",vb=".$vb.",width=".$width.",height=".$height.",acodec=mp3,ab=".$ab.",channels=2}:standard{access=http{mime=\"".$mimetype."\"},mux=".$mux.",dst=".$vlc_stream."/".$channel."}\n");
/* Update the channel status in the log file. */
fprintf($log_ptr,"%s, %s: Channel %s streaming with transcoding to %s. Audio stream %d is selected.\n",date("Y-m-d H:i:s"),$_SERVER['REMOTE_ADDR'],$channel,$vcodec,$audio);
}
read_until_prompt($vlc_ptr);
fputs($vlc_ptr,"control ".$channel." play\n");
read_until_prompt($vlc_ptr);
/* Das folgende Konstrukt spricht sowohl den Internet Explorer als auch Firefox an.
Für den Internet-Explorer wird das <object>-Tag ausgeführt, aber der Inhalt des <comment>-Tags überlesen.
Für Firefox wird im <object>-Tag alles bis auf den Inhalt des <comment>-Tags überlesen. Letzteres wird aber dann ausgeführt. */
if ($mux == "ts") {
print("<object classid=\"clsid:E23FE9C6-778E-49D4-B537-38FCDE4887D8\" codebase=\"http://downloads.videolan.org/pub/videolan/vlc/latest/win32/axvlc.cab\" mimetype=\"".$mimetype."\" width=\"".$width."\" height=\"".$height."\" id=\"vlc\" events=\"True\">\n");
print("<param name=\"Src\" value=\"http://".$public_add."/".$channel."\" />\n");
print("<param name=\"ShowDisplay\" value=\"True\" />\n");
print("<param name=\"AutoPlay\" value=\"True\" />\n");
print("<param name=\"Volume\" value=\"100\" />\n");
print("<embed src=\"http://".$public_add."/".$channel."\" mimetype=\"".$mimetype."\" border=\"2\" width=\"".$width."\" height=\"".$height."\" id=\"vlc\"></embed>\n</object><hr>\n");
/* User Interface with icons. */
print("<table width=\"100%\" cellspacing=\"1\" cellpadding=\"4\" bgcolor=\"beige\"><tr>\n");
print("<td width=\"11%\" align=\"center\" valign=\"center\"><input type=\"image\" src=\"/gnome-icons/actions/media-playback-start.png\" class=\"submit\" alt=\"Play\" onClick=\"document.vlc.play();\"></td>\n");
print("<td width=\"11%\" align=\"center\" valign=\"center\"><input type=\"image\" src=\"/gnome-icons/actions/media-playback-pause.png\" class=\"submit\" alt=\"Pause\" onClick=\"document.vlc.pause();\"></td>\n");
print("<td width=\"11%\" align=\"center\" valign=\"center\"><input type=\"image\" src=\"/gnome-icons/status/audio-volume-muted.png\" class=\"submit\" alt=\"Mute\" onClick=\"document.vlc.toggleMute();\"></td>\n");
print("<td width=\"11%\" align=\"center\" valign=\"center\"><input type=\"image\" src=\"/gnome-icons/actions/view-fullscreen.png\" class=\"submit\" alt=\"Full Screen\" onClick=\"document.vlc.fullscreen();\"></td>\n");
print("<td width=\"56%\" align=\"center\" valign=\"center\"><form action=\"".$_SERVER['PHP_SELF']."\" method=\"post\">\n");
print("<input type=\"hidden\" name=\"state\" value=\"3\">\n");
print("<input type=\"hidden\" name=\"channel\" value=\"".$channel."\">\n");
print("<input type=\"image\" src=\"/gnome-icons/actions/media-playback-stop.png\" class=\"submit\" alt=\"Stop\">");
print("</form></td>\n</tr></table>\n");
/* User Interface with text buttons. */
print("<table width=\"100%\" cellspacing=\"1\" cellpadding=\"2\"><tr>\n");
print("<td width=\"11%\" align=\"center\" valign=\"center\"><input type=\"button\" class=\"submit\" style=\"background-color:aquamarine;font-weight:bold\" value=\"Play\" onClick=\"document.vlc.play();\"></td>\n");
print("<td width=\"11%\" align=\"center\" valign=\"center\"><input type=\"button\" class=\"submit\" style=\"background-color:aquamarine;font-weight:bold\" value=\"Pause\" onClick=\"document.vlc.pause();\"></td>\n");
print("<td width=\"11%\" align=\"center\" valign=\"center\"><input type=\"button\" class=\"submit\" style=\"background-color:aquamarine;font-weight:bold\" value=\"Mute\" onClick=\"document.vlc.togglemute();\"></td>\n");
print("<td width=\"11%\" align=\"center\" valign=\"center\"><input type=\"button\" class=\"submit\" style=\"background-color:aquamarine;font-weight:bold\" value=\"Full Screen\" onClick=\"document.vlc.fullscreen();\"></td>\n");
print("<td width=\"56%\" align=\"center\" valign=\"center\"><form action=\"".$_SERVER['PHP_SELF']."\" method=\"post\">\n");
print("<input type=\"hidden\" name=\"state\" value=\"3\">\n");
print("<input type=\"hidden\" name=\"channel\" value=\"".$channel."\">\n");
print("<input type=\"submit\" value=\"Exit\" style=\"background-color:lightcoral;font-weight:bold\">");
print("</form></td>\n</tr></table>\n");
} else {
print("<object id=\"mediaPlayer\" classid=\"CLSID:22d6f312-b0f6-11d0-94ab-0080c74c7e95\" codebase=\"http://activex.microsoft.com/activex/controls/mplayer/en/nsmp2inf.cab#Version=5,1,52,701\" standby=\"Loading Microsoft Windows Media Player components...\" type=\"application/x-oleobject\">\n");
print("<param name=\"fileName\" value=\"http://".$public_add."/".$channel."\">\n");
print("<param name=\"animationatStart\" value=\"true\">\n");
print("<param name=\"transparentatStart\" value=\"true\">\n");
print("<param name=\"autoStart\" value=\"true\">\n");
print("<param name=\"showControls\" value=\"true\">\n");
print("<param name=\"Volume\" value=\"-100\">\n");
print("<embed src=\"http://".$public_add."/".$channel."\" mimetype=\"".$mimetype."\" border=\"2\" width=\"".$width."\" height=\"".$height."\" id=\"mediaPlayer\"></embed>\n</object><hr>\n");
/* User Interface with 'Exit' buttons. */
print("<form action=\"".$_SERVER['PHP_SELF']."\" method=\"post\">\n");
print("<input type=\"hidden\" name=\"state\" value=\"3\">\n");
print("<input type=\"hidden\" name=\"channel\" value=\"".$channel."\">\n");
print("<table cellspacing=\"1\" cellpadding=\"4\" bgcolor=\"beige\"><tr>\n");
print("<td><input type=\"image\" src=\"/gnome-icons/actions/media-playback-stop.png\" class=\"submit\" alt=\"Stop\"></td>\n");
print("<td><input type=\"submit\" value=\"Exit\" style=\"background-color:lightcoral;font-weight:bold\"></td>\n</tr></table>\n");
print("</form>\n");
}
break;
case 3:
/* Stop the transmission and delete the channel. After this, run through to the default stage. */
fputs($vlc_ptr,"control ".$channel." stop\n");
read_until_prompt($vlc_ptr);
fputs($vlc_ptr,"del ".$channel."\n");
read_until_prompt($vlc_ptr);
/* Store the deleted channel in the log file. */
fprintf($log_ptr,"%s, %s: Channel %s destroyed.\n",date("Y-m-d H:i:s"),$_SERVER['REMOTE_ADDR'],$channel);
default:
print ("<h1>Caipithek - Movie Selector</h1>\n");
/* Check the number of active channels. */
fputs($vlc_ptr,"show media\n");
fgets($vlc_ptr,10);
/* Get the number of broadcast channels which have already been set up. */
preg_match_all ("/\b([0-9]{1,}) broadcast\b/",fgets($vlc_ptr,38),$output,PREG_SET_ORDER);
$broadcasts = $output[0][1];
/* If channels have been defined, examine them and remove the "dead" ones. */
if ($broadcasts) {
/* Read existing channel. */
$channel = trim(fgets($vlc_ptr,20));
$loop = true;
unset ($dead_channels);
do {
/* Check if the current channel is transcoded or only streamed. */
$is_streamed = chk_stream($vlc_ptr);
read_until_instances($vlc_ptr);
/* Continue to read until a '>', a digit ([0-9]) or a word starting with 'i' (for 'instances') is encountered. */
do $char = fgetc($vlc_ptr);
while (strpos(">Vi",$char) === false);
if ($char == '>') {
/* This channel is not active. Put the channel number into the list of dead channels. */
$dead_channels[] = $channel;
/* Decrease the number of broadcasts. */
$broadcasts--;
/* Read the following space char. */
fgetc($vlc_ptr);
$loop = false;
} elseif ($char == 'i') {
/* This channel is active. Overread all information until a line with the word 'playlistindex' is read. */
do;
while (substr(trim(fgets($vlc_ptr,40)),0,13) != "playlistindex");
/* Despite the channel being active - check whether the stream is transcoded or streamed only.
If the channel is streamed only, decrease $broadcasts as streaming uses little CPU power only. */
if ($is_streamed)
$broadcasts--;
/* Read next character. */
$char = fgetc($vlc_ptr);
if ($char == '>') {
/* Read the following space char and abort the loop. */
fgetc($vlc_ptr);
$loop = false;
} else {
/* Another channel declaration is following. Concatenate the read digit with the rest of the digits. */
$channel = trim(fgets($vlc_ptr,20));
}
} else {
/* The current channel is not active. Put the channel number into the list of dead channels. */
$dead_channels[] = $channel;
/* Decrease the number of broadcasts. */
$broadcasts--;
/* Another channel declaration is following. Concatenate the "V" with the rest of the digits. */
$channel = "V".trim(fgets($vlc_ptr,20));
}
} while ($loop);
if (isset($dead_channels))
/* If dead channels exist, delete them all. */
foreach ($dead_channels as $channel) {
/* Delete the dead channel and write a log entry. */
fputs($vlc_ptr,"del ".$channel."\n");
read_until_prompt($vlc_ptr);
fprintf($log_ptr,"%s, %s: Channel %s purged.\n",date("Y-m-d H:i:s"),$_SERVER['REMOTE_ADDR'],$channel);
}
}
if (($broadcasts >= $max_streams) and !$is_local) {
/* If the client is not local and the maximum number of transcoded streams has been exceded, refuse any further streaming. */
print ("<p>I am sorry but the maximum number of transcoded streams (<b>".$max_streams."</b>) for this server has already been reached.</p>\n");
print ("<p>Please try this page again later.</p>\n");
print ("<form action=\"".$_SERVER['PHP_SELF']."\" method=\"post\">\n");
print ("<input type=\"hidden\" name=\"state\" value=\"1\">\n");
print ("<input type=\"submit\" value=\"Retry\" style=\"background-color:springgreen;font-weight:bold\">\n");
print ("</form>");
/* Store the service refusal in the log file. */
fprintf($log_ptr,"%s, %s: Maximum number of streams (%d) reached.\n",date("Y-m-d H:i:s"),$_SERVER['REMOTE_ADDR'],$max_streams);
} else {
/* Read the list of movies and display the selector. */
$mov_ptr = fopen ($movie_list,"r") or die ("The file $movie_list could not been found.");
print ("<p>Select up to <b>".$max_inputs."</b> movies from the list for streaming:</p>\n");
print ("<form action=\"".$_SERVER['PHP_SELF']."\" method=\"post\">\n");
print ("<select name=\"movies[]\" multiple=\"multiple\" size=\"20\">\n");
while (!feof($mov_ptr)) {
$movie_name = strtok(fgets($mov_ptr),":");
if ($movie_name) {
$width = strtok(":");
$height = strtok(":");
$video_streams = strtok(":");
$audio_streams = strtok(":");
$duration = strtok(":");
$hours = (int) ($duration / 3600);
$mins = (int) (($duration % 3600) / 60);
$secs = $duration % 60;
/* The value that is transmitted for each selected movie, comprises the movie name, the image width and the image height, separated by ':'. */
printf ("<option value=\"%s:%d:%d:%d\">%s [%d x %d] [%d-%d] (Dauer: %d:%02d:%02d)</option>\n",base64_encode($movie_name),$width,$height,$audio_streams,$movie_name,$width,$height,$video_streams,$audio_streams,$hours,$mins,$secs);
}
}
print ("</select>\n");
print ("<p>Adjust the streaming options and click on the <b>Stream</b> button to proceed or on the <b>Clear</b> button to clear your selection.</p>\n");
if ($is_local)
print ("<p>Access from a <b>local network</b> has been detected. Additional bandwidth options and pure streaming are available therefore.</p>\n");
print ("<table border bgcolor=\"lavender\" cellspacing=\"3\" cellpadding=\"5\">\n<tr><th bgcolor=\"tan\">Video Codec</th><th bgcolor=\"#E7C69A\">Bandwidth</th><th bgcolor=\"#FCD8A8\">Audio Stream</th></tr>\n");
if ($broadcasts < $max_streams) {
/* If the number of transcoded streams has not yet been exceeded, show the options for the video codec and for the bandwidth. */
if ($is_local)
print ("<tr><td bgcolor=\"tan\"><input type=\"radio\" name=\"vcodec\" value=\"h264\"> H.264<br>\n");
else
/* Pre-select H.264 for remote clients. */
print ("<tr><td bgcolor=\"tan\"><input type=\"radio\" name=\"vcodec\" value=\"h264\" checked> H.264<br>\n");
print ("<input type=\"radio\" name=\"vcodec\" value=\"mp4v\"> MPEG 4<br>\n");
print ("<input type=\"radio\" name=\"vcodec\" value=\"mp2v\"> MPEG 2<br>\n");
print ("<input type=\"radio\" name=\"vcodec\" value=\"WMV2\"> WMV 2</td>\n");
/* Show Bandwidth Options */
print ("<td bgcolor=\"#E7C69A\">");
print ("<input type=\"radio\" name=\"bw\" value=\"1\"> 256 kbps<br>\n");
if ($is_local) {
/* If the access is made from the local subnet, offer additional bandwidth options and do not preselect anything. */
print ("<input type=\"radio\" name=\"bw\" value=\"2\"> 384 kbps<br>\n");
print ("<input type=\"radio\" name=\"bw\" value=\"3\"> 448 kbps<br>\n");
print ("<input type=\"radio\" name=\"bw\" value=\"4\"> 544 kbps<br>\n");
print ("<input type=\"radio\" name=\"bw\" value=\"5\"> 1152 kbps</td>\n");
} else {
/* If the access is made from a remote network, offer only bandwidth options until 544 kbps. Pre-select 384 kbps. */
print ("<input type=\"radio\" name=\"bw\" value=\"2\" checked> 384 kbps<br>\n");
print ("<input type=\"radio\" name=\"bw\" value=\"3\"> 448 kbps<br>\n");
print ("<input type=\"radio\" name=\"bw\" value=\"4\"> 544 kbps</td>\n");
}
/* Show Audio Stream Options */
print ("<td bgcolor=\"#FCD8A8\">");
print ("<input type=\"radio\" name=\"audio\" value=\"1\" checked> 1<br>\n");
print ("<input type=\"radio\" name=\"audio\" value=\"2\"> 2<br>\n");
print ("<input type=\"radio\" name=\"audio\" value=\"3\"> 3</td></tr>\n");
}
if ($is_local)
/* If the client is local, show the pure streaming option and pre-select it. */
print ("<tr><td bgcolor=\"moccasin\" colspan=\"3\"><input type=\"radio\" name=\"vcodec\" value=\"stream\" checked> Pure Streaming</td></tr>\n");
print ("</table><br>\n");
/* Show the 'Start' and 'Clear' button. */
print ("<input type=\"hidden\" name=\"state\" value=\"2\">\n");
print ("<input type=\"submit\" value=\"Start\" style=\"background-color:springgreen;font-weight:bold\">\n");
print ("<input type=\"reset\" value=\"Clear\" style=\"background-color:lightcoral;font-weight:bold\">\n");
print ("</form>");
fclose ($mov_ptr);
}
break;
}
/* Close telnet session to VLC server process. */
fclose ($log_ptr);
fputs($vlc_ptr,"exit\n");
fclose ($vlc_ptr) or die ("VLC Socket cannot be closed.");
?>
</body>
</html>
Ist alles richtig installiert, sollte man das PHP-Skript aufrufen und Videos wiedergeben können. Viel Spaß beim Schauen!
DLNA-Server
Die Digital Living Network Alliance (DLNA) hat sich zum Ziel gesetzt, die Interoperabilität zwischen verschiedenen Multimediageräten zu fördern [1] und dazu verschiedene Standards und Zertifizierungen ausgearbeitet.
Geräte, welchen diesen Standards entsprechen, werden umgangssprachlich meist kurz als “dlna-fähig” bezeichnet. Befinden sich beispielsweise ein dlna-fähiger Fernseher und ein dlna-fähiger Medien-Server im gleichen (Heim-) Netzwerk, so “findet” der Fernseher die vom Medien-Server angebotenen Medien (Filme, Lieder, Fotos) automatisch. Erreicht wird dies dadurch, dass der Medien-Server periodisch Multicast-Pakete ins Netz schickt, welche vom Fernseher gelesen werden. Der Fernseher “weiß” damit, dass es einen oder mehrere Medien-Server im Netzwerk gibt und wie er diese ansprechen kann. Umgekehrt schickt auch der Fernseher Multicast-Pakete ins Netz und kündigt sich daduch als Medien-Client an, so dass er von verschiedenen Medien-Servern erkannt werden kann. Benutzt man den Windows Media Player unter Windows Vista, so bekommt man beispielsweise eine Mitteilung in der Task-Leiste darüber, dass ein Medien-Client im Netzwerk erkannt wurde, und man wird gefragt, ob man seine Filme, Lieder und Fotos freigeben möchte.
Um den Caipirinha-Server dnla-fähig zu machen, habe ich verschiedene Programme ausprobiert und bin schließlich auf das Paket minidlna gestoßen, welches sich sehr leicht einrichten läßt. Das Paket enthält eigentlich nur eine Konfigurationsdatei und eine ausführbare Datei, welche lediglich 2MB groß ist. Die Konfigurationsdatei ist übersichtlich gehalten und hat nur wenige Einstellungen:
/etc/minidlna.conf:
# port for HTTP (descriptions, SOAP, media transfer) traffic
port=8202
# network interface to bind to (this is the only interface that will serve files)
#network_interface=eth0
# set this to the directory you want scanned.
# * if have multiple directories, you can have multiple media_dir= lines
# * if you want to restrict a media_dir to a specific content type, you
# can prepend the type, followed by a comma, to the directory:
# + "A" for audio (eg. media_dir=A,/home/jmaggard/Music)
# + "V" for video (eg. media_dir=V,/home/jmaggard/Videos)
# + "P" for images (eg. media_dir=P,/home/jmaggard/Pictures)
media_dir=A,/home/public/Audio
media_dir=P,/home/public/Bilder
media_dir=V,/home/public/Video
# set this if you want to customize the name that shows up on your clients
#friendly_name=My DLNA Server
# set this if you would like to specify the directory where you want MiniDLNA to store its database and album art cache
db_dir=/var/cache/minidlna
# this should be a list of file names to check for when searching for album art
# note: names should be delimited with a forward slash ("/")
album_art_names=Cover.jpg/cover.jpg/AlbumArtSmall.jpg/albumartsmall.jpg/AlbumArt.jpg/albumart.jpg/Album.jpg/album.jpg/Folder.jpg/folder.jpg/Thumb.jpg/thumb.jpg
# set this to no to disable inotify monitoring to automatically discover new files
# note: the default is yes
inotify=yes
# set this to yes to enable support for streaming .jpg and .mp3 files to a TiVo supporting HMO
enable_tivo=no
# set this to strictly adhere to DLNA standards.
# * This will allow server-side downscaling of very large JPEG images,
# which may hurt JPEG serving performance on (at least) Sony DLNA products.
strict_dlna=no
# default presentation url is http address on port 80
#presentation_url=http://www.mylan/index.php
# notify interval in seconds. default is 895 seconds.
notify_interval=600
# serial and model number the daemon will report to clients
# in its XML description
serial=12345678
model_number=1
Unter port legt man fest, auf welchem Port der Medien-Server auf Anfragen lauschen soll. Mit dem Eintrag media_dir legt man die Verzeichnisse fest, die von minidlna angeboten werden sollen. Der Eintrag db_dir verweist auf ein Verzeichnis, in welchem minidlna eine kleine Datenbank verwaltet. Dieses Verzeichnis legt man an mit:
mkdir /var/cache/minidlna chown wwwrun:www /var/cache/minidlna
wenn man, wie hier, minidlna später unter der Benutzerkennung wwwrun laufen lassen will. Mit notify_interval legt man die Zeitintervalle in Sekunden fest, in denen der DLNA-Server seine Multicast-Pakete ins Netzwerk verschickt.
Schließlich verschiebt man die ausführbare Datei minidlna aus dem Installationspaket nach /usr/sbin und startet den DLNA-Server in einer root-Shell mit su -l wwwrun -c '/usr/sbin/minidlna'. Der DNLA-Server läuft dann unter der Benutzerkennung wwwrun.
In der Log-Datei /var/cache/minidlna/minidlna.log werden eventuell
auftretende Fehler protokolliert; es empfiehlt sich daher eine
regelmäßige Kontrolle.
Dieses Setup habe ich unter openSuSE 11.1/11.2 in der 64-Bit-Version und unter openSuSE 11.0 in der 32-Bit-Version erfolgreich getestet. Beim Austesten mit einem Fernseher des Typs Sony Bravia 46W5800 hat sich gezeigt, dass man hochauflösende Filme in XviD oder DivX mit Hilfe von ffmpeg und diesen Optionen für den Sony Bravia 46W5800 transkodieren kann:
ffmpeg -i film.avi -target film-dvd -s 1920x1080 film.mpg